最近遇到了几个大模型模型算法应用的关键问题,作为记录。
Agent 设计范式
目前主流的 AI Agent(智能体)设计模式,通常不是单一的,而是基于一些核心思想和框架的组合。这些设计模式旨在赋予大语言模型自主思考、规划、行动和反思的能力,以完成更复杂的任务。
1. ReAct (Reasoning and Acting)
这是目前最流行、最基础也是最核心的一种 Agent 设计模式。它的核心思想是让大语言模型在一个“思考-行动-观察”的循环中持续工作,直到任务完成。
- 思考(Thought):LLM 会根据当前任务和过往观察,产生一段内部思考,比如“我需要找到XX信息,我应该使用什么工具?”
- 行动(Action):LLM 根据思考,生成一个调用外部工具的指令(即 Function Call)。
- 观察(Observation):LLM 接收到外部工具返回的结果。
这个循环会反复进行,直到 LLM 判断任务已完成并生成最终回复。这种模式将”思考”过程显性化,使得模型的决策过程更加透明和可控。
2. Plan-and-Execute(规划与执行)
这种模式更侧重于对复杂任务的结构化分解。它将一个大任务分为两个阶段:
- 规划阶段(Planning):LLM 首先会分析用户的请求,并生成一个详细的、分步骤的行动计划。这个计划是固定的,不会在执行过程中轻易改变。
- 执行阶段(Execution):LLM 严格按照规划好的步骤,一步一步地调用工具和执行任务。
这种模式的优点是任务流程清晰、稳定,适合需要按部就班完成的复杂任务。但缺点是缺乏灵活性,如果计划中的某个步骤失败,Agent 可能无法自主调整。
3. Self-Correction(自我纠正/反思)
这种设计模式的核心是让 Agent 具备复盘和纠错的能力。它通常与其他模式结合使用,为 Agent 增加一个”反思”步骤。
- 反思(Reflection):Agent 在完成一个任务或得到一个结果后,会重新评估这个结果是否正确或达到预期。
- 纠正(Correction):如果评估结果不理想,Agent 会根据反思结果,修改其原始的思考路径或行动计划,然后再次尝试,直到达到满意的结果。
这种模式能显著提升 Agent 在复杂问题上的表现,因为它允许 Agent 从错误中学习,避免重复犯错。
这三种模式并不是相互独立的。一个强大的 Agent 通常会结合使用这些思想:例如,一个 Agent 可能先用 Plan-and-Execute 进行任务分解,然后在每个执行步骤中,使用 ReAct 循环来调用工具,并最终用 Self-Correction 机制来验证和修正结果。
大模型如何”用”工具?Agent、Function Call 与 MCP 的进化之路
在构建基于大语言模型(LLM)的应用时,一个核心挑战是让 LLM 不只停留在”聊天”,而是真正具备”行动”能力,比如联网搜索、调用 API 或执行代码。这就是 Agent 的核心思想:让 LLM 像一个智能体一样,能够根据用户的指令,自主决定是直接回答,还是调用外部工具来获取信息或完成任务。
1. Agent 的决策过程:LLM 如何知道何时调用工具?
Agent 的决策机制本质上是 Prompt Engineering 的一种高级应用。开发者会设计一个精巧的 Prompt,将可用的工具列表、它们的用途和描述一并告诉 LLM。
例如,当我们问一个 Agent:“今天北京的天气怎么样?”它的思考过程可能如下:
- 用户意图分析: 用户想知道北京的天气。
- 工具匹配: 我有一个可以查询天气的工具(
get_weather(location))。 - 决策与执行: 我需要调用这个工具,并把“北京”作为参数。
这个思考过程并不神秘,而是通过精心设计的 Prompt 来引导 LLM 生成。LLM 会根据输入的指令和工具描述,在输出中”思考”并生成一个结构化的行动指令,然后由外部程序(Agent 框架)去实际执行。
2. Function Call (FC):将决策能力内置到模型中
Function Call (FC) 是对上述 Agent 决策机制的一种原生优化。它将“思考”和“生成调用指令”的能力直接通过模型训练内置进去。
FC 的核心是: 模型能够根据上下文,直接以预先定义好的 JSON 格式 生成对外部工具的调用,而不是像传统 Agent 那样需要外部框架去解析 LLM 生成的文本。
这是一种巨大的进步,因为它使得工具调用更加稳定、高效,并减少了外部解析的复杂性。
那么,为什么说 FC 存在“MxN”的问题?
这里有一个常见的误解:很多人以为每增加一个工具,就需要重新训练模型。这是不正确的。
FC 的”MxN”问题不在于模型本身,而在于 工具的描述格式。每个拥有 FC 能力的 LLM 平台(如 OpenAI, Google, Anthropic)都有自己独特的工具描述 Schema(函数签名)。一个搜索工具,为了能被不同的模型调用,开发者需要为它编写 M 份不同的描述文档。同样,一个 Agent 开发者如果想使用 N 个工具,并支持 M 个不同的 LLM,就需要处理 MxN 个兼容性问题。
简而言之,FC 解决了“让模型知道如何调用工具”的问题,但没有解决“工具描述格式不统一”的问题。
3. MCP:通过抽象层实现真正的解耦
Multi-tool Coordinator Protocol (MCP) 正是为了解决 FC 带来的兼容性与扩展性问题而诞生的。
MCP 的核心思想是:在模型和工具之间增加一个抽象的中间层。
这个中间层通常由一个 MCP Server 组成,其工作流程如下:
- 工具注册: 所有外部工具都按照一套统一的 MCP 协议 接入并注册到 MCP Server。
- Agent (LLM) 接入: 所有的 Agent 只需要学习并支持这套统一的 MCP 协议。它们不再需要知道每个工具的具体描述细节,只需向 MCP Server 发送一个统一的请求,来获取可用的工具列表或执行工具调用。
为什么说 MCP 实现了“M+N”?
- M 个不同的模型(或 Agent)只需要对接 1 个统一的 MCP Server。
- N 个不同的工具也只需要对接 1 个统一的 MCP Server。
通过这种方式,模型与工具之间不再是复杂的点对点连接,而是通过一个中心化的枢纽进行通信。这不仅解决了 FC 在不同平台间的兼容性问题,更是一种架构上的巨大优化,它让工具的管理、维护和扩展变得前所未有的简单。
总结来说:
- Agent 是让 LLM 具备行动能力的 思想。
- Function Call 是将这种思想 内置到模型中 的一种能力。
- MCP 是在此基础上,进一步将 模型与工具解耦 的一种 架构设计。
当然,MCP 还需要在调用端封装。在典型的 MCP (Multi-tool Coordinator Protocol) 实现中,会区分 AI Host (AI 宿主) 和 MCP Client (MCP 客户端) 这两个角色,它们通过一种清晰的协作模式来共同完成任务。
AI Host (AI 宿主)
- 角色: AI Host 是整个系统的核心,通常是运行大语言模型(LLM)或 Agent 框架的那部分。它负责接收用户的指令,并进行高级别的决策与推理。
- 职责:
- 接收用户输入。
- 与 LLM 交互,进行意图分析。
- 根据 LLM 的输出,决定是直接生成回复还是需要调用工具。
- 注意: AI Host 不直接与具体的工具交互,它只知道 MCP 协议。
MCP Client (MCP 客户端)
- 角色: MCP Client 是一个独立的模块或库,作为 AI Host 与 MCP Server 之间的桥梁。它封装了所有与 MCP Server 通信的细节。
- 职责:
- 将来自 AI Host 的工具调用请求,按照 MCP 协议 进行格式化,并发送给 MCP Server。
- 接收 MCP Server 返回的结果,并将其转换回 AI Host 可理解的格式。
- 管理与 MCP Server 的连接和会话。
- 注意: MCP Client 也不关心具体的工具是如何实现的,它只负责协议层面的通信。
整个 MCP 协作过程可以分解为以下几个步骤:
- 用户请求: 用户向 AI Host 发出指令,例如:“帮我查一下旧金山的天气。”
- AI Host 意图分析: AI Host 将用户指令发送给内置的 LLM。LLM 基于其 Function Call 或 ReAct 能力,判断出需要调用一个天气查询工具。它会生成一个结构化的调用请求,比如
{"tool_name": "weather_api", "parameters": {"city": "旧金山"}}。 - AI Host 委托: AI Host 拿到 LLM 生成的调用请求后,并不会自己去执行,而是将其 委托 给 MCP Client。
- MCP Client 协议转换与发送: MCP Client 接收到这个请求,将其封装成符合 MCP 协议的格式(例如一个特定的 HTTP POST 请求或 gRPC 调用),然后发送给远端的 MCP Server。
- MCP Server 工具协调与执行: MCP Server 接收到请求后,根据
tool_name找到对应的工具,将parameters传递给该工具并执行。 - 结果返回: 工具执行完毕,结果返回给 MCP Server,MCP Server 再将结果通过 MCP 协议返回给 MCP Client。
- MCP Client 结果转换与回传: MCP Client 接收到 MCP Server 的响应,将其解析并转换为 AI Host 可理解的格式,然后返回给 AI Host。
- AI Host 回复生成: AI Host 拿到工具执行结果(例如:”旧金山今天多云,气温 15 摄氏度”),将其作为上下文的一部分再次输入给 LLM,最终由 LLM 生成完整的自然语言回复给用户。
通过这种方式,AI Host 始终保持”干净”,只关心高级别的推理和决策,而具体的工具调用和协议通信的复杂性则完全由 MCP Client 和 MCP Server 这层抽象来处理,实现了 AI 能力与工具生态的彻底解耦。
最后,通过一个图说明 FC 和 MCP 工作模式:
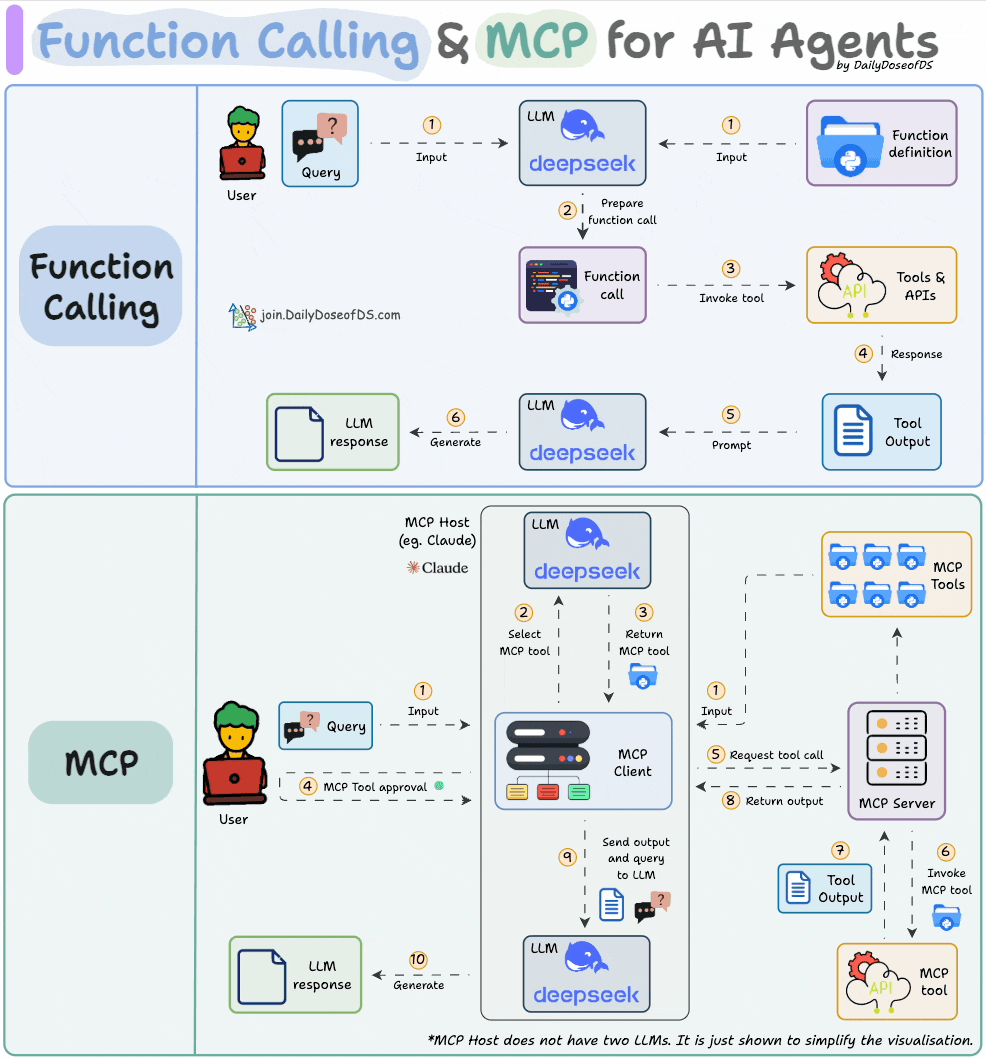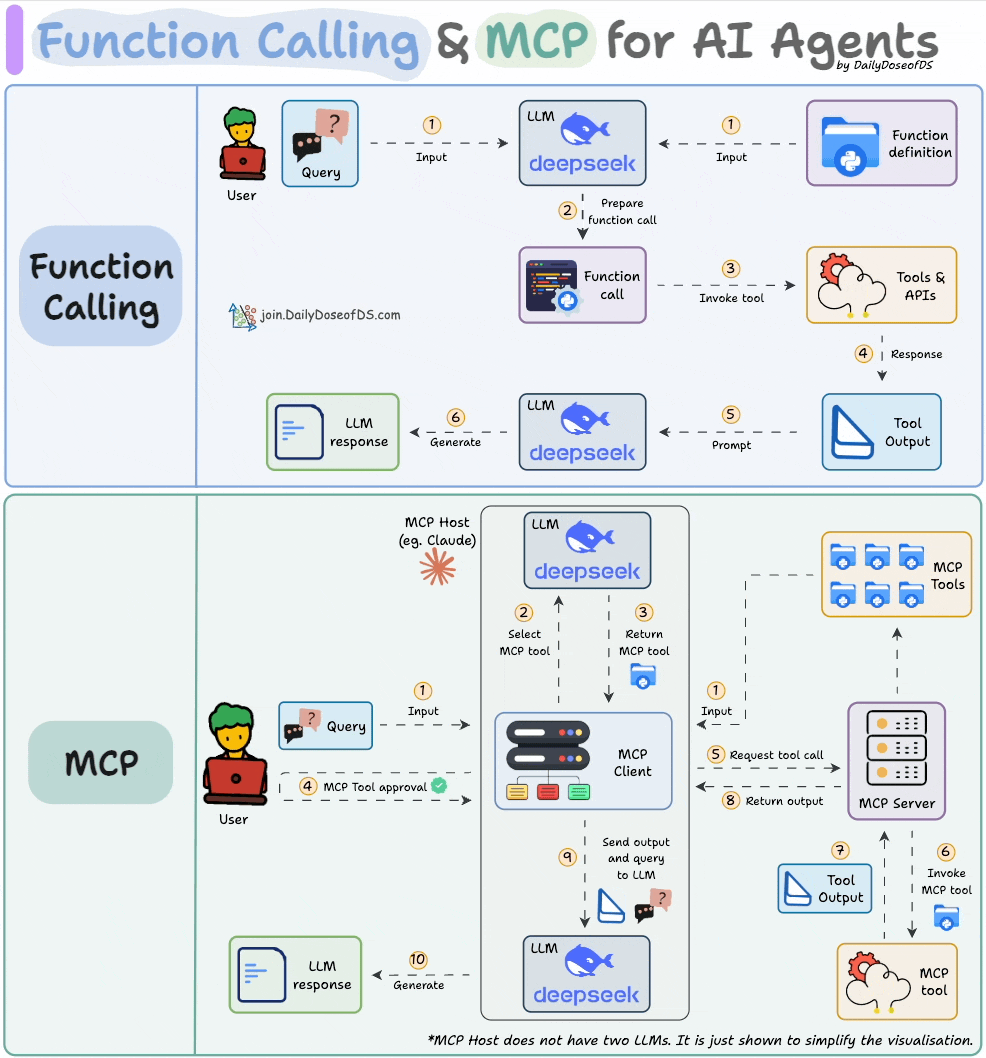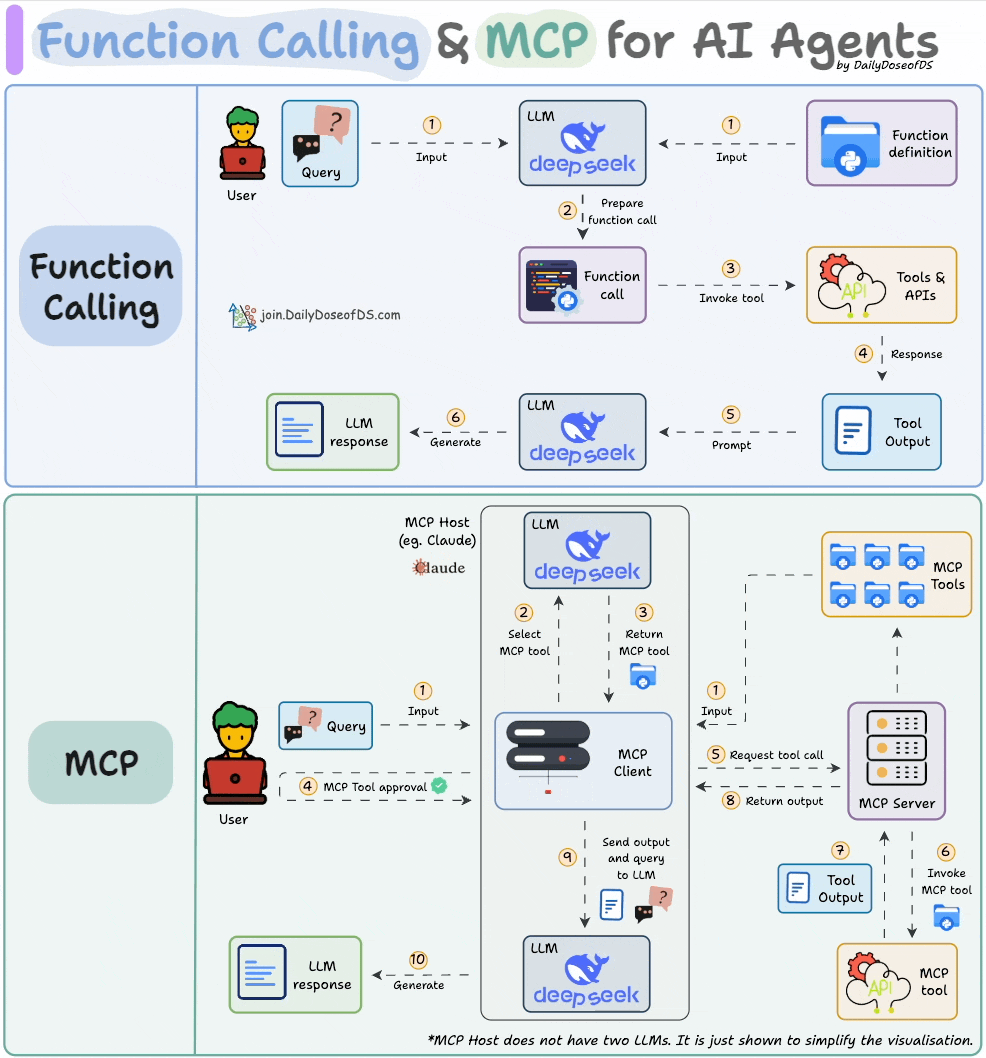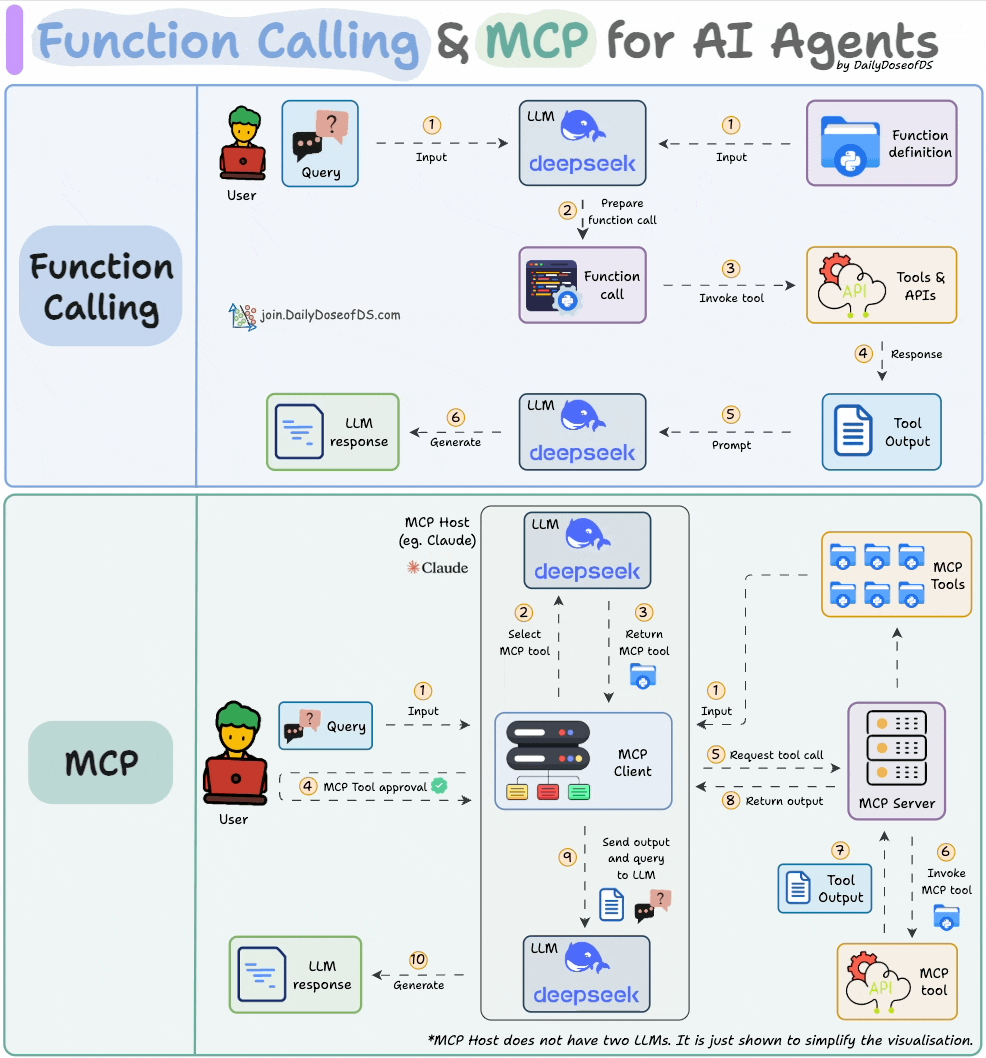
JSON 格式化输出
在 Function Call (FC) 模式下,要保证模型稳定输出 JSON 格式,主要依赖于 模型本身的训练和微调。
如何保证模型稳定输出 JSON?
这并非单纯通过 Prompt Engineering 就能完美解决的问题。核心在于:
- 大规模训练: 在模型的预训练和指令微调阶段,会使用大量的包含 JSON 格式的结构化数据作为训练样本。这些样本告诉模型,当它接收到特定类型的指令(例如,要求它调用某个工具)时,应该输出一个遵循特定 JSON Schema 的结果。
- 特殊的解码策略: 一些模型在解码时会采用特殊的约束,比如 JSON Schema 约束解码。这意味着,模型在生成每一个 token 时,都会检查其是否符合预先定义的 JSON 格式规则。如果生成的 token 会导致 JSON 格式无效,模型会将其“回溯”并尝试生成另一个 token,直到生成完整且正确的 JSON。这种方法极大地提高了输出的稳定性和正确性。
- Prompt 工程辅助: 尽管核心能力来自模型本身,但好的 Prompt 仍然至关重要。例如,在 Prompt 中清晰地描述工具的函数签名,并明确要求模型“请以 JSON 格式输出调用结果”,可以进一步引导模型输出期望的格式。
比如这个 FC 输出的格式:
1 | { |
其中的每个 key 和 value 都要非常精准的匹配到调用的工具才可以。
MCP 是否也要求模型输出固定格式?
是的,但要求的是更简单、更统一的格式。
MCP 的核心理念是 解耦。它将工具的复杂性和多样性从模型端剥离,因此模型不需要了解每个工具具体的 JSON Schema。模型唯一需要知道的,是与 MCP Client 交互的 统一协议。
这个统一协议的格式通常非常简单,比如一个包含 tool_name 和 parameters 的 JSON 对象。模型需要做的,只是稳定输出这个简单的、所有工具都通用的 JSON 格式,然后由 MCP Client 去处理后续的协议转换和工具调用。
这正是 MCP 的优势所在:它降低了对模型的要求。模型不需要针对每一个新工具去学习其独特的调用格式,它只需要掌握一套通用的、简单的输出格式即可。这使得模型可以更专注于其核心的自然语言理解和意图识别,而将复杂的
工具协调任务交给 MCP Client 和 MCP Server 去完成。
下面是一个模型输出的 MCP 格式的调用:
1 | { |
这个看起来比较类似,但实际上模型并不知道 weather_api 到底是什么,也不知道对于一个 city,应该传入的参数是什么(city?location?),对于温度单位,也类似。
FC (Function Call) 模式下,模型的难度体现在 “量” 上。模型需要记忆并理解每一个工具独特的 JSON Schema,而且要非常精确。如果你的系统有 100 个不同的工具,每个工具的参数都不一样,那模型就需要稳定地输出 100 种不同结构的 JSON。这就像让一个人记住 100 个完全不同的表格格式,并根据指令填写。
而 MCP (Multi-tool Coordinator Protocol) 模式下,模型的难度只体现在 “质” 上。它只需要学会一种 统一且简单的 JSON 格式,即 {“tool_name”: “…”, “parameters”: {…}}。无论有多少个工具,这个输出格式始终不变。这就像让一个人永远只填写一种固定格式的表格,然后把表格交给一个“总机”去处理后续的细节。
MCP Client 拿到的模型输出,也就是通用且简单的 JSON 格式(例如:{“tool_name”: “…”, “parameters”: {…}}),负责将其解析、封装、调用 Server、接收响应、解析响应,回传给 AI Host。