虽然了解大模型训练中的 RLHF 训练,但是都是有点不够深刻,特别是 PPO 算法的细节。
看到一篇好文章,转载并重新编辑,加入个人理解,以便日后查阅。有兴趣可以参考原文
引言
强化学习属于机器学习的一个分支,区别于有监督学习。关键点在于:
- 无监督,没有标签,通过试错和奖励来优化行为和策略。
- 与环境有交互。(抽象概念,不要深究)
- 没有明确的反馈(无标签),反馈是通过奖励信号传递的,可以是延迟的,需要考虑长期回报。
强化学习的简化图: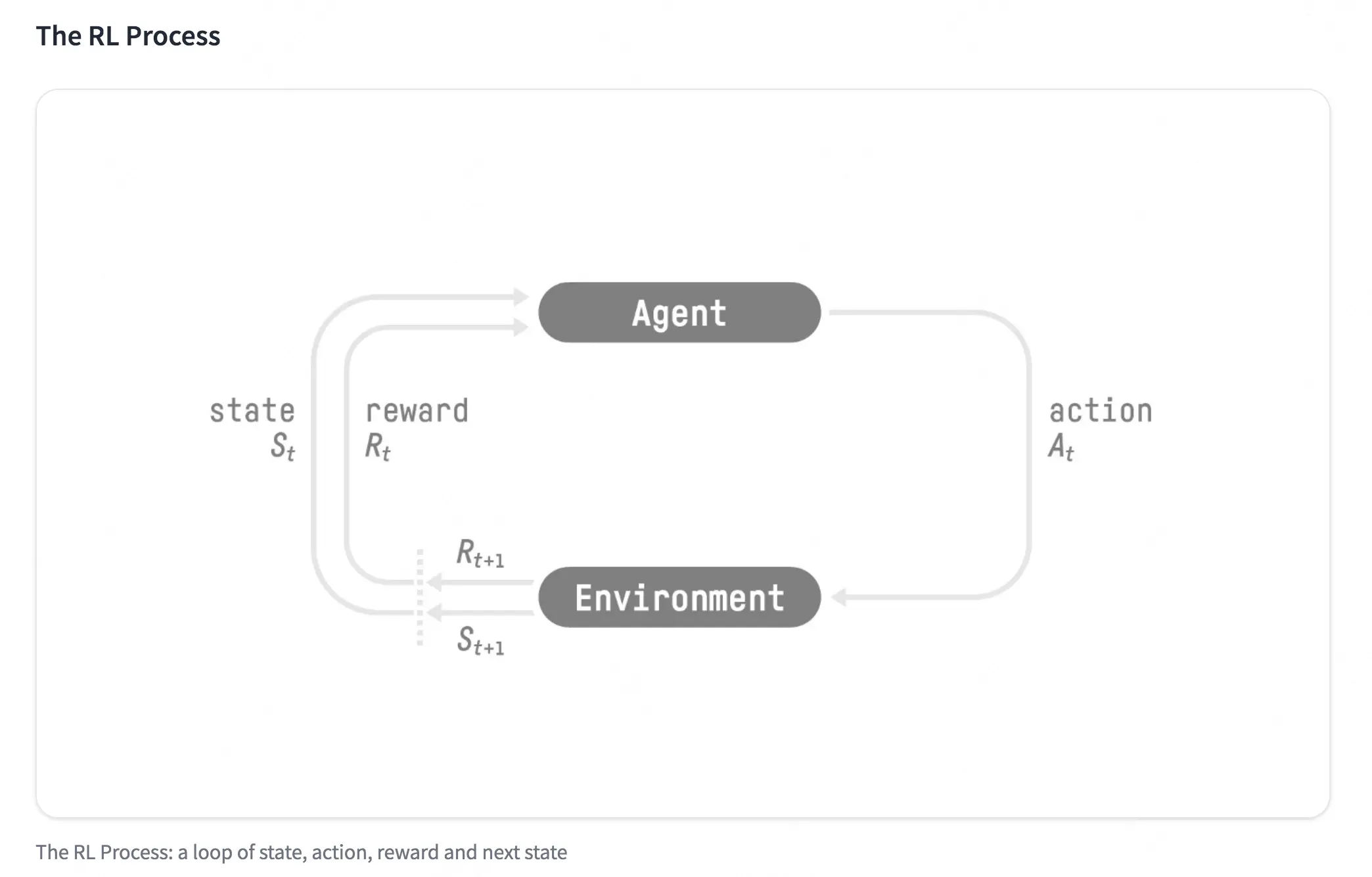
强化学习的两个实体:智能体(Agent)与环境(Environment)。强化学习中两个实体的交互:
- 状态空间 S:S 即为 State,指环境中所有可能状态的集合
- 动作空间 A:A 即为 Action,指智能体所有可能动作的集合
- 奖励 R:R 即为 Reward,指智能体在环境的某一状态下所获得的奖励。
一个交互过程可以表示为:
- 在 $t$ 时刻,智能体处于状态 $S_t$,在该状态下,得到的奖励为 $R_t$;
- 根据 $S_t$、$R_t$ 以及策略智能体选择动作 $A_t$;
- 执行动作 $A_t$ 后环境转移到状态 $S_{t+1}$,智能体获得奖励 $R_{t+1}$。
智能体在这个过程中学习,它的最终目标是:找到一个策略,这个策略根据当前观测到的环境状态和奖励反馈,来选择最佳的动作。
价值函数
奖励 $R$ 是一个标量,但是在实际问题中,一个动作,既有即时奖励,也要考虑长期回报。为了解决这个问题,引入了价值函数的概念。
其中:
- $V_t$:表示在 $t$ 时刻的状态 $S_t$ 下的价值(包含了即时和未来的奖励)。
- $R_t$:$t$ 时刻的即时收益。
- $\gamma$:是折扣因子,用于平衡当前奖励和未来奖励。
这里最需要注意的是:$V_{t+1}$ 同样包含了现在和未来的奖励,但是对于 $V_{t}$ 来说,它就相当于未来潜在收益。
NLP 和强化学习
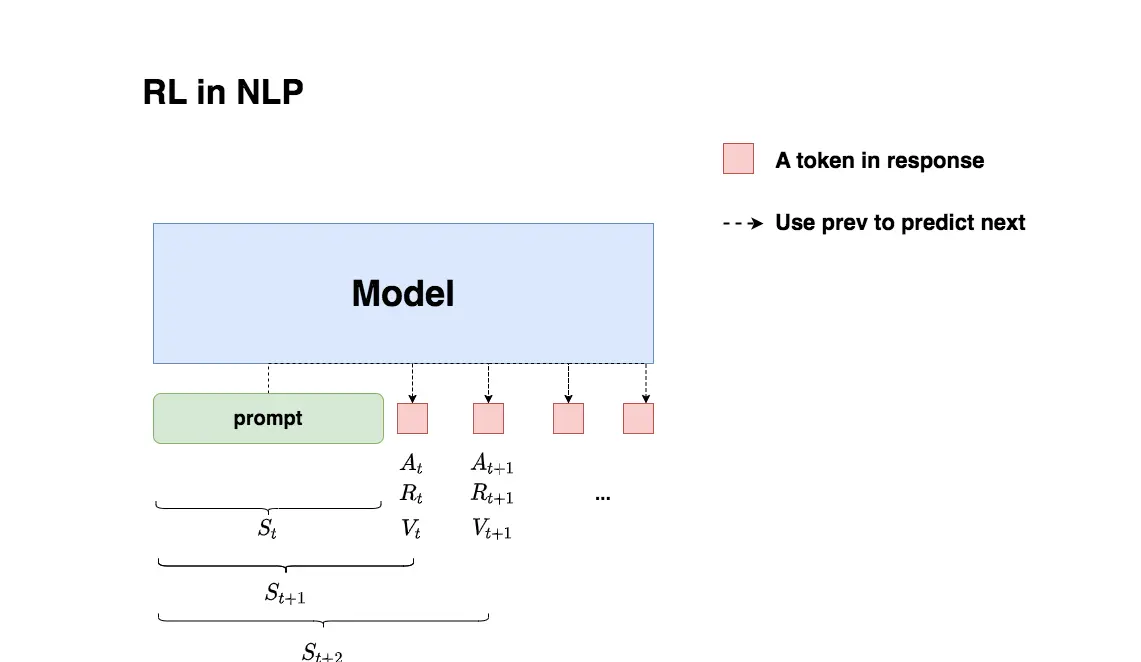
这里的 NLP 是特指生成模型。
生成模型的推理执行过程:给模型一个 prompt,让模型能生成符合人类喜好的 response。再回想一下 GPT 模型做推理的过程:每个时刻 $t$ 只产生一个 token,即 token 是一个一个蹦出来的,先有上一个 token,再有下一个 token。
结合上面的图,分解一下这个过程:
- 智能体就是生成模型。
- 在 $t$ 时刻,有上下文 context($S_t$),模型产出一个 token,对应 RL 中的动作,记为 $A_t$。动作空间就是词表。
- 在 $t$ 时刻,有了 $A_t$ 动作,即时收益为 $R_t$,总收益为 $V_t$(注意二者不一样)。对于生成模型,收益是什么?人类喜好。
- 状态变化,$S_{t+1}$ 变为 $S_t$ 和新生成的 token。
- 忽略图中的下表,主要理解过程和对应的东西。
$A_t$ 是产出一个新 token,$S_t$ 是词表空间,$R_t$ 和 $V_t$ 是什么?答案是通过模型产生的分数,这里不要在意命名,你叫评价模型,叫奖励模型都行,只不过是两个打分模型而已。
记住,到此已经有了3 个模型了啊,$A_t$ 模型表示智能体的动作,$R_t$ 和 $V_t$ 是两个打分模型,分别表示即时奖励和未来长期奖励。
还有一个重要的点:不是生成一个 token,也就是有一个动作,我们就要计算奖励、打分,可以等生成模型回答完毕(也就是 EOS token)再打分。
RLHF 中的 4 个模型
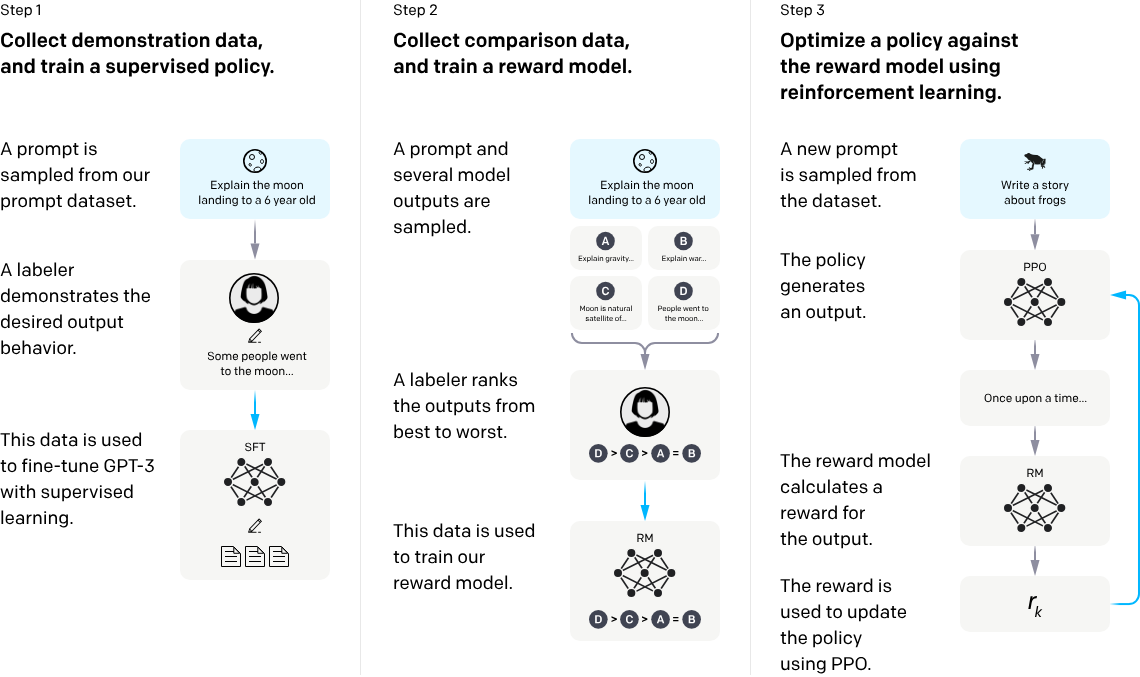
OpenAI 的示意图:
RLHF 中使用的模型示意图:
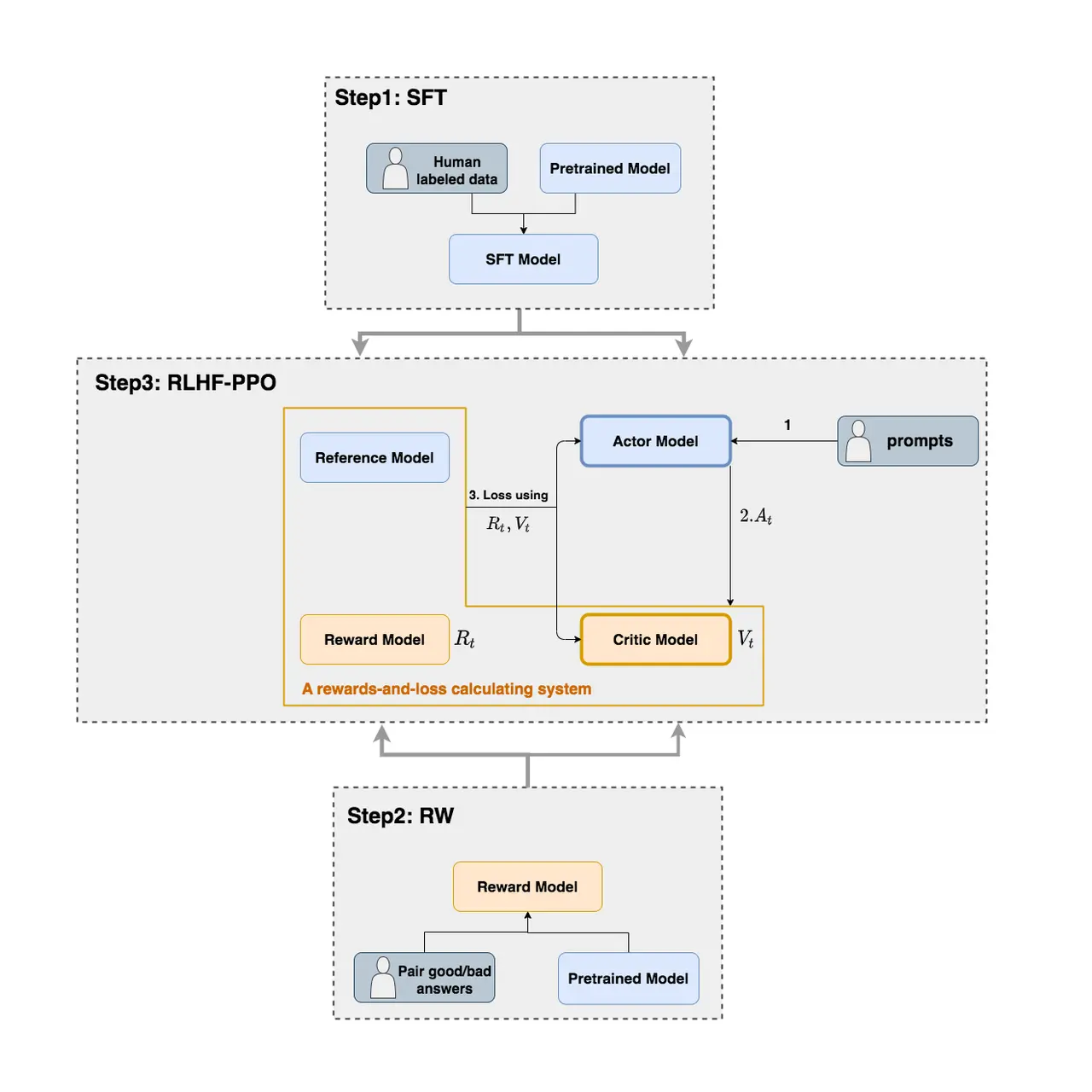
现在大家都知道 PPO 有 4 个模型,上面我们说了 3 个,还有 1 个,这里将 4 个模型都列出来:
- Actor Model:PPO 训练的模型,也是我们最终要用于应用的模型。
- Critic Model:价值函数,反映的是当前环境和状态下,该动作的预期长期收益 $V_t$。
- Reward Model:奖励函数,一个标量,表示当前prompt+响应的整体质量,也是上面的 $R_t$。
- Reference Model:这个模型是额外增加的,主要是在 RLHF 阶段给语言模型增加一些”约束”,防止语言模型训歪(朝不受控制的方向更新,效果可能越来越差)。这个看 Loss 就能明白了。
再次强调一下奖励模型和价值模型的区别:
Reward Model (奖励模型) RM
- 作用: 它是根据人类偏好数据训练出来的模型,用来取代传统 RL 中的手动奖励函数。
- 计算对象 (即时收益): RM 的输出是一个标量分数,表示 (提示 Prompt + 完整响应 Response) 这个序列的整体质量。
- 结论: RM 给出的是对整个生成序列的即时/单一评估分数,但这个分数代表的是对最终整体表现的评估。在 RLHF 中,它为强化学习提供了一个稀疏 (Sparse) 的奖励信号。
Critic Model (评论家模型) V
- 作用: 评估当前状态(State)或状态-动作对(State-Action Pair)的长期价值,指导 Actor(即 LLM 本身)的策略更新。
- 计算对象 (整体收益): V 的输出是一个标量分数,表示从当前状态($s$)开始,遵循当前策略一直到结束所能获得的期望累积折扣奖励 (Expected Cumulative Discounted Reward),即 $V(s) = \mathbb{E}[\sum_{t’=t}^{T} \gamma^{t’-t} r_{t’}]$。
- 结论: V 估算的是未来的整体收益。它通过时序差分 (Temporal Difference, TD) 学习,帮助解决强化学习中的信用分配问题 (Credit Assignment Problem)。
哪些模型需要更新参数?
Actor Model 和 Critic Model。Actor 肯定是很好理解的,所以不多说了,Critic Model 为什么也要更新?主要是这里存在一个难点:怎么评估潜在收益呢?我们自己随口一说评估总体收益,但是这个是很难的,因为没有真的标签(有监督)。所以我们需要通过一个模型来判断,而且更重要的是,这个判断模型的能力,要不断提升能力,才能做好这件事。
Actor Model
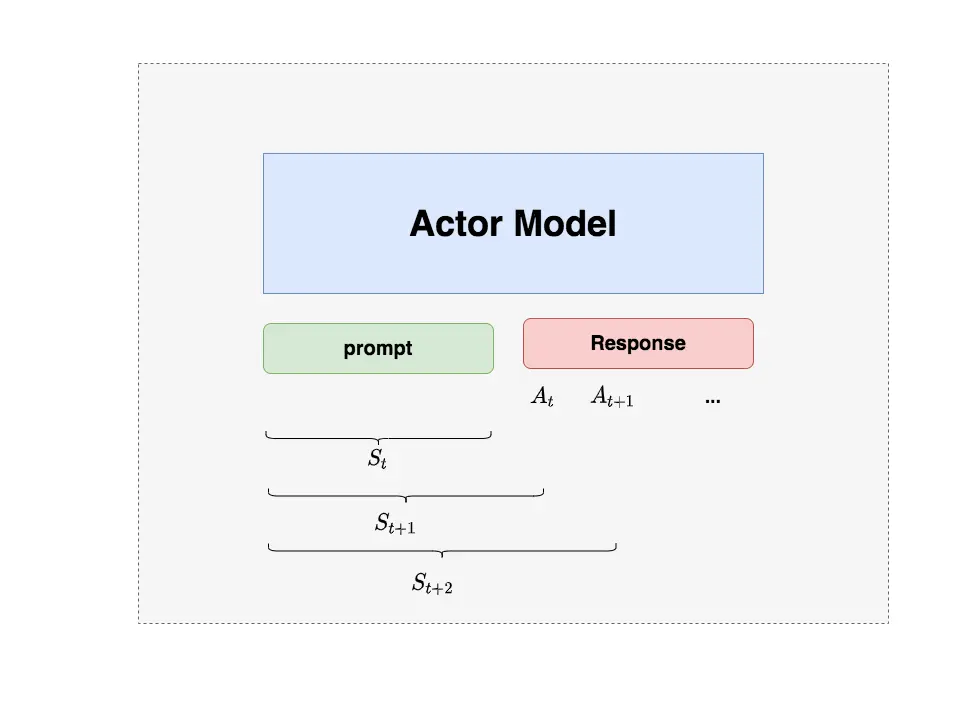
我们的最终目的是让 Actor 模型能产生符合人类喜好的 response。所以我们的策略是,先喂给 Actor 一条 prompt(这里假设 batch_size = 1,所以是 1 条 prompt),让它生成对应的 response。然后,我们再将”prompt + response”送入我们的”奖励-loss”计算体系中去算得最后的 loss,用于更新 actor。
Reference Model
Reference Model 一般也用 SFT 阶段得到的 SFT 模型做初始化,在训练过程中,它的参数是冻结的。Ref 模型的主要作用是防止 Actor”训歪”,那么它具体是怎么做到这一点的呢?
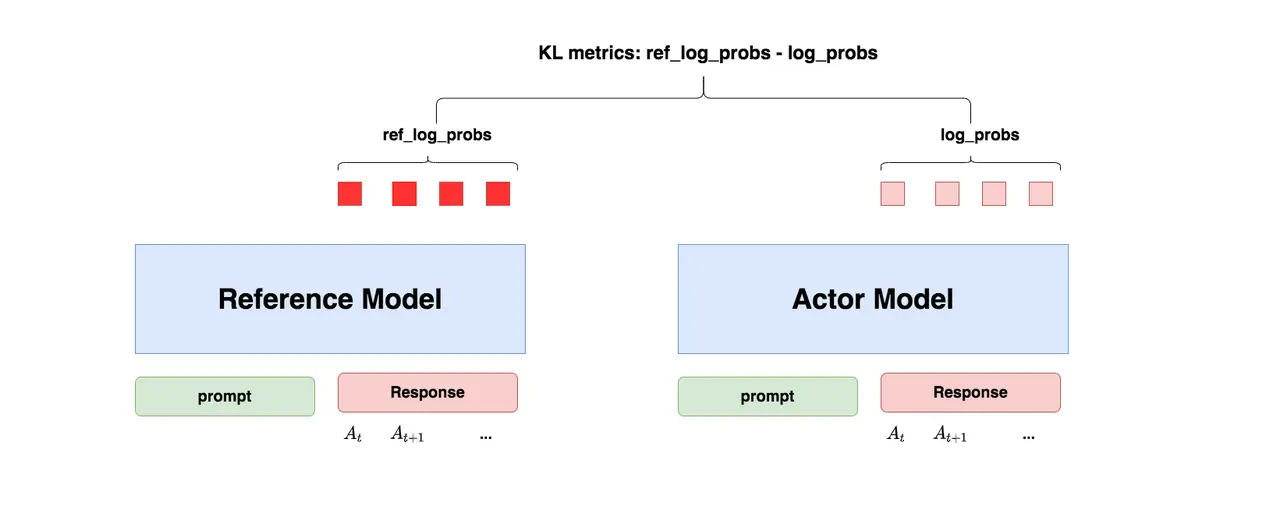
“防止模型训歪”换一个更详细的解释是:我们希望训练出来的 Actor 模型既能达到符合人类喜好的目的,又尽量让它和 SFT 模型不要差异太大。简言之,我们希望两个模型的输出分布尽量相似。那什么指标能用来衡量输出分布的相似度呢?我们自然而然想到了KL 散度。
简单来说就是防止模型”高分低能”,过拟合到乱七八糟但是得分高的回答上。
关于 KL 散度和 ref 模型的计算,这里不需要展开,网上资料特别多。
Reference Model 输入和 Actor Model 一致,输出是一个参考答案。
Critic Model
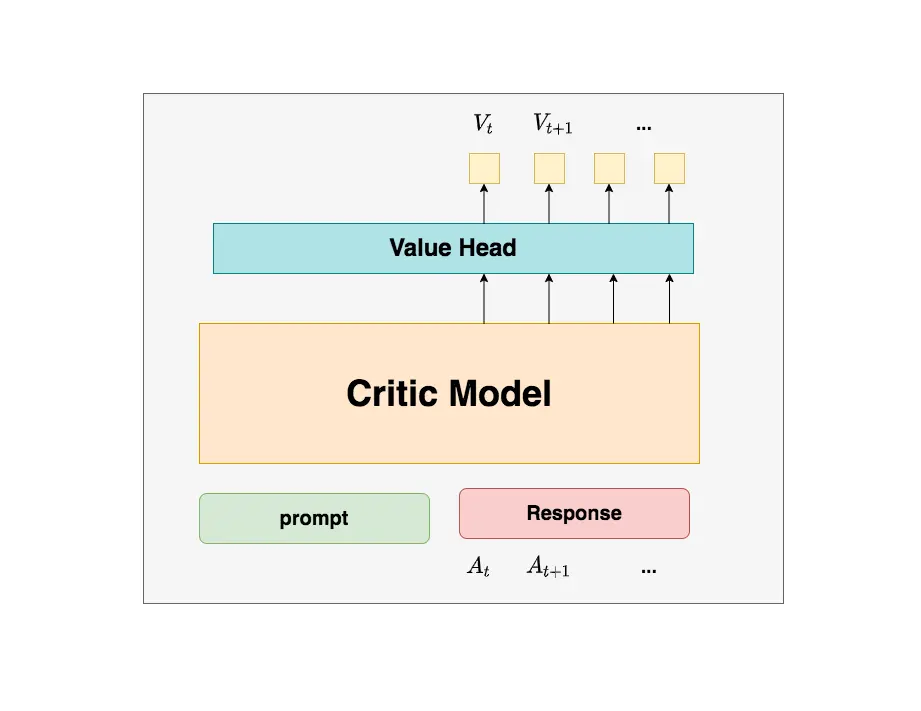
前面已经讲了这个模型的作用以及为什么要更新参数。简单讲一下这个模型怎么训练的:一般都是采用了 Reward 模型作为它的初始化,所以这里我们也按 Reward 模型的架构来简单画画它。你可以简单理解成,Reward/Critic 模型和 Actor 模型的架构是很相似的(毕竟输入都一样),同时,它在最后一层增加了一个 Value Head 层,该层是个简单的线形层,用于将原始输出结果映射成单一的 $V_t$ 值。
特别要注意:
- 价值函数是一个计算 Actor Model 在生成过程中每个 token 的价值(一个标量)。那么它的输入就是当前的问题 + Actor Model 当前的输出(并非完整的答案)
- 价值标量是怎么得到的呢?将最后一个 token(认为包含了整个序列 token 的注意力)的隐藏层(4096 维)输入到一个 1 维的 FC 层,就输出一个标量。
Reward Model
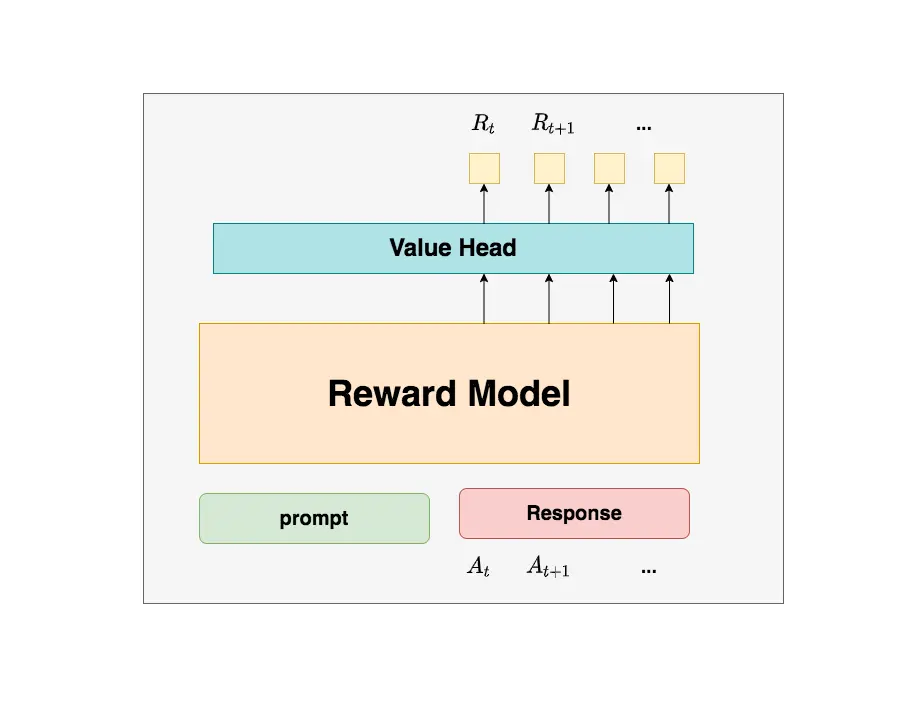
计算整体奖励,也没啥好讲的,提前训练好的(RLHF 第二阶段做的事情),这里重点讲一下为啥 reward 模型不需要更新参数呢?
其实我觉得不要深入去纠结,我感觉 PPO 这么做的原因就是为了引入一个客观的、绝对的标准。这个模型最重要的区别在于,它只关心当前这个 response 的好坏。Critic 隐含了综合考虑所有 response 的好坏的含义(需要才需要更新参数)。
特别要注意:
- 奖励函数是一个计算 Actor Model 在生成的完整的答案的奖励,所以输入是当前的问题 + 完整的答案,得到一个标量奖励。
- 奖励的标量是怎么得到的呢?将输入的最后一个 token(认为包含了整个序列 token 的注意力)的隐藏层(4096 维)输入到一个 1 维的 FC 层,就输出一个标量。
RLHF 的 Loss 计算
我已经看过太多次了,所以不想重新写这个了,直接看原文或者网上搜一下就知道了。注意每一项对应 ref、critic、reward 模型,结合前面讲解的各个模型的作用,应该能很好地理解这个 Loss 的含义。
这里重点讲一下如何计算每次 Token 的优势估计。
PPO (使用 GAE) 中每个 Token 优势估计的计算逻辑核心目标是计算 $\mathbf{A}(s_t, a_t)$,即在状态 $s_t$ 采取动作 $a_t$ 的额外好处。
步骤 1:计算 Token 级别的即时奖励 ($r_t$)。
- $r_{\text{RM}, t}$ (稀疏 RM 奖励):
- $t = 1 \text{ 到 } T-1$ (中间 token): $0$
- $t = T$ (最后一个 token): $r_{\text{final}}$ (RM 的输出)
- KL 惩罚项: 每个 token 都有一个负值 (如果 Policy 偏离 SFT 模型)。
结果: 得到了一个包含稀疏 RM 信号和密集 KL 惩罚的 token 序列即时奖励 $[r_1, r_2, \dots, r_T]$。
步骤 2:计算 Critic 模型的时序差分 (TD) 误差 ($\delta_t$)
这是 GAE 的基础,结合 $r_t$ 和 Critic 模型 $V$ 的结果。
- $V(s_t)$ 和 $V(s_{t+1})$: 由 Critic Model 对 token 序列的隐藏状态进行评估所得。
- $\delta_t$ 衡量了实际观测到的短期收益($r_t + \gamma V(s_{t+1})$)与 模型原本估计的长期收益($V(s_t)$)之间的差异。
步骤 3:使用 GAE 平滑估计优势函数 ($\mathbf{A}_t$)最后,使用 GAE 公式,将一系列 TD 误差平滑地组合起来,得到最终用于 PPO 策略更新的优势估计: