ASR 流程中,音频特征提取是第一步。和 CV 不同,图片本身的 RGB 数值就是一种特征,但是音频本身无法被用于分析,常常是将一段音频提取 FBank 和 MFCC 特征然后作为模型的输入。
语音参数提取特征的步骤:预增强->分帧->加窗->添加噪声->FFT->Mel滤波->对数运算->DCT。其中 FFT 和 DCT 是快速傅里叶变换和离散余弦变换。
音频预处理
预增强(Pre-Emphasis)
预增强一般是数字语音信号处理的第一步。语音信号往往会有频谱倾斜(Spectral Tilt)现象,即高频部分的幅度会比低频部分的小,预增强在这里就是起到一个平衡频谱的作用,增大高频部分的幅度。它使用如下的一阶滤波器来实现:
分帧(Framing)
输入的音频信号是一段连续,一般流式的有几百毫秒,非流式的有几秒或者更长,需要将信号分成短时帧。做这一步的原因是:信号中的频率会随时间变化(不稳定的),一些信号处理算法(比如傅里叶变换)通常希望信号是稳定,也就是说对整个信号进行处理是没有意义的,因为信号的频率轮廓会随着时间的推移而丢失。为了避免这种情况,需要对信号进行分帧处理,认为每一帧之内的信号是短时不变的。一般设置帧长取 20ms~40ms,相邻帧之间 50\%(+/-10\%)的覆盖。对于 ASR 而言,通常取帧长为 25ms,帧移为 10ms(不重叠部分)。
加窗
在分帧之后,通常需要对每帧的信号进行加窗处理。目的是让帧两端平滑地衰减,这样可以降低后续傅里叶变换后旁瓣的强度,取得更高质量的频谱。常用的窗有:矩形窗、汉明(Hamming)窗、汉宁窗(Hanning),以汉明窗为例,其窗函数为:
随机添加噪声(可选)
有时候我们需要进行数据增强,会手动合成一些音频。某些人工合成的音频可能会造成一些数字错误,诸如 underflow 或者 overflow。 这种情况下,通过添加随机噪声可以解决这一类问题。公式如下:
$q$ 用于控制添加噪声的强度,$rand()$ 产生 $[-1.0, 1.0)$ 的随机数。
注意:Kaldi 中是在分帧之后的下一步添加随机噪声
特征提取
人耳对声音频谱的响应是非线性的,经验表明:如果我们能够设计一种前端处理算法,以类似于人耳的方式对音频进行处理,可以提高语音识别的性能。FilterBank就是这样的一种算法。FBank 特征提取要在预处理之后进行,这时语音已经分帧,我们需要逐帧提取 FBank 特征。
快速傅里叶变换(FFT)
我们分帧之后得到的仍然是时域信号,为了提取 FBank 特征,首先需要将时域信号转换为频域信号。傅里叶变换可以将信号从时域转到频域。傅里叶变换可以分为连续傅里叶变换和离散傅里叶变换,因为我们用的是数字音频(而非模拟音频),所以我们用到的是离散傅里叶变换。数学公式如下:
对每一帧加窗后的音频信号做 N 点的 FFT 变换,也称短时傅里叶变换(STFT),N通常取256或512,然后用如下的公式计算能量谱:
FBank(Filter Banks)特征
经过上面的步骤之后,在能量谱上应用 Mel 滤波器组,就能提取到FBank特征。
在介绍Mel滤波器组之前,先介绍一下 Mel 刻度,这是一个能模拟人耳接收声音规律的刻度,人耳在接收声音时呈现非线性状态,对高频的更不敏感,因此 Mel 刻度在低频区分辨度较高,在高频区分辨度较低,与频率之间的换算关系为:
Mel 滤波器组就是一系列的三角形滤波器,通常有 40 个或 80 个,在中心频率点响应值为 1,在两边的滤波器中心点线性衰减到 0,如下图:
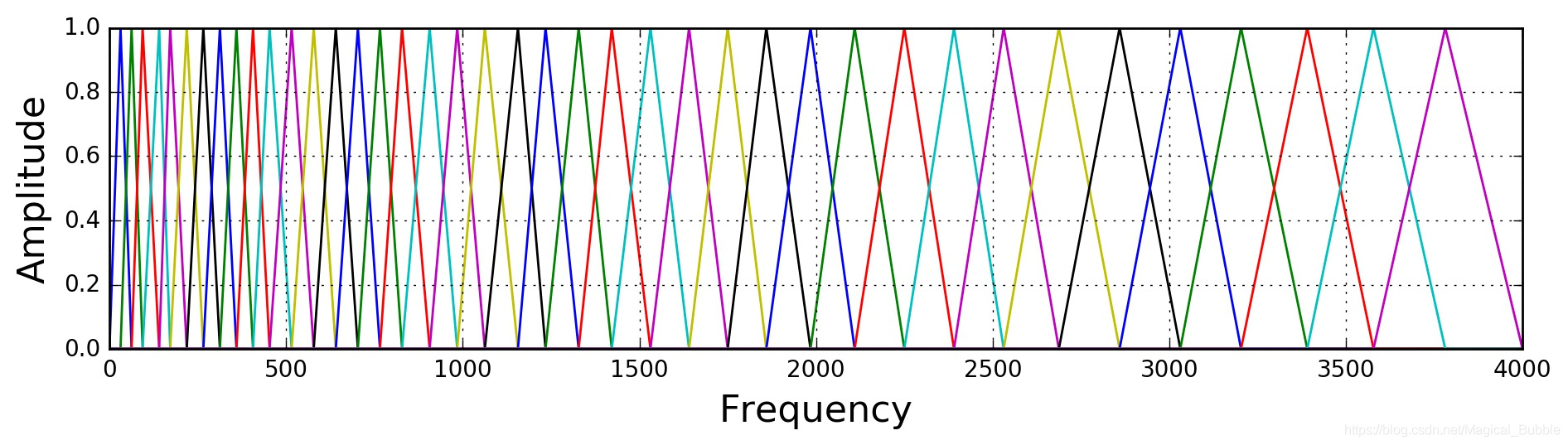
具体公式就不写了,网上可查。
在能量谱上应用 Mel 滤波器组,其公式为:
其中,$k$ 表示 FFT 变换后的编号,$m$ 表示 Mel 滤波器的编号。
MFCC(Mel-frequency Cepstral Coefficients)特征
前面提取到的 FBank 特征,往往是高度相关的。因此可以继续用 DCT 变换,将这些相关的滤波器组系数进行压缩。对于 ASR 来说,通常取 2~13 维,扔掉的信息里面包含滤波器组系数快速变化部分,这些细节信息在 ASR 任务上可能没有帮助。
DCT 变换其实是逆傅里叶变换的等价替代:
所以 MFCC 名字里面有倒谱(Cepstral)。
一般对于ASR来说,对 MFCC 进行一个正弦提升(sinusoidal liftering)操作,可以提升在噪声信号中最后的识别率:
从公式看,猜测原因可能是对频谱做一个平滑,如果 $D$ 取值较大时,会加重高频部分,使得噪声被弱化。
python 实现
https://gist.github.com/murphypei/dcae63c9de780586a70a89603bd0f2c2