anchor 是一类目标检测方法种的一个核心概念,其本质是一个预设的框,但是这个框也为 loss 计算带来一些麻烦。
对于一般的目标检测 loss 计算,通常分为几部分。比如 yolo 系列分为 objectness(是否包含目标)、classification(目标分类)、boundingbox-regression(目标位置)。其中,每个样本都需要计算 objectness 得分的损失,正样本需要计算 classification 和 bbox-regression 损失,其中每种损失又有不同的计算方式和组合方法,比如 bbox-regression 有 D_IoU、G_IoU、C_IoU 等等,组合方法有 Focal Loss 等等。但是这些不是我们这篇文章关注的重点。
对于目标检测我们要搞明白一个核心问题:如何生成参与 loss 计算的样本?anchor 和 ground-truth 的纠缠不休就是在这个问题上,各种框混杂一起。要搞明白这个问题,我们把带 anchor 的目标检测中出现各种框的核心概念一一剥开。
一般来说,带 anchor 的目标检测包含以下几种框:
- ground-truth,简称 gt,标注生成的框,包含位置信息和类别信息。
- anchor,也成为先验框,尺寸预先设置好的框,一般在 feature map 上,每个像素点(也称为 cell)有多个,每个大小形状都不一样。可以通过 k-means 等方法生成适合数据集的尺寸,同时大小不同的尺寸也和模型的多个检测分支对应。
- predict,也称为预测框,网络的 detect 层的输出信息,大小通常是 [n, h, w, (nc + 4 + 1)],n 表示 feature map 上每 cell 的 anchor 数量,h 和 w 是 feature map 的大小,nc 表示类别得分,4 表示位置信息,1 表示 objectness 得分。
写的越多越杂乱,所以不写太多计算,只要记住这些核心概念,下面来说明每种框之间的关联:
- anchor 和 gt 相互作用,通过筛选手段,确定哪个 anchor 负责预测哪个 gt,不同检测方法中筛选手段不同,并且有的规定一个 gt 必须有一个 anchor 负责预测,有的则选择忽略某些 gt,有的一个 gt 可以有多个 anchor 对应。
- predict 和 anchor 一一对应。首先可以明确,每个 predict 都是对应一个 anchor 的(其实现在大部分检测方法比如 yolo,predict 输出的并不是实际坐标,需要通过 anchor 解码)。当 1 中确定某个 anchor 有负责预测 gt 之后,这个 anchor 对应的 predicts 就是正样本,其余就是负样本。predicts 的输出结果和 gt 相互作用,计算 loss。
总结以上核心:正负样本通常由 gt 和先验框 anchor 匹配生成,参与计算的是 anchor 的和 gt(只有尺寸,没有类别),而计算 loss 则是其对应的 predict 和 gt(包含类别信息)。这句话就点明了 3 种框的关系,可以看出 anchor 是桥梁,非常重要。
有了以上概念,我们来实际操作解读以下经典的目标检测中一些具体实际操作。
Faster-RCNN
我的老朋友,最爱。faster-rcnn 属于 two-stage,anchor 主要是在第一层 RPN 中用到。我们知道 RPN 用于生成 RoI。我们把 RPN 网络输出的就是 predicts,那么如何计算 Loss 呢?
依据上述步骤,首先就是 anchor 和 gt 的匹配。在 faster-rcnn 中分为:
- 初始化每个 anchor 的 mask 为 -1,-1 表示这个 anchor 被忽略,不参与 loss 计算。
- 计算每个 gt 和 每个 anchor 的 iou。
- 对于一个 anchor,如果其和所有 gt 的 iou 都小于阈值 neg_iou_thr,则标记为负样本,mask 设为 0;如果最大 iou 大于阈值 pos_iou_thr,则标记为正样本。此时有一些 gt 是没有 anchor 负责预测的,这一步的意思是挑选优质的正样本和负样本。
- 对于所有 gt,如果其和某个 anchor 的 iou 大于阈值 min_pos_iou,则也将这些 anchor 标记为正样本,min_pos_ios <= pos_iou_thr。这一步是为了增加正样本的数量(如果不需要增加正样本数量,则可以设置只和最大 iou 的 anchor 匹配),一个 gt 可能会由多个 anchor 负责预测。通过本步骤,可以最大程度保证每个 gt 都有 anchor 负责预测,如果还是小于 min_pos_iou,那就没办法了,这个 gt 被忽略了。这一步引入的 anchor 因为 iou 较少,质量较低。
上述规则将 anchor 标记分类(anchor_target_layer 实现),正样本都有对应的 gt 用于计算 bbox-regression 损失,同时正负样本本身又可以用于计算 objectness loss,直接将每个 anchor 对应的 predict 带入计算即可。没有用到的 anchor(标记为 -1),计算 loss 的时候被忽略。另外,RPN 没有 classification 损失。
YOLO V2/V3
one-stage 最爱。废话少说,yolo v2 步骤如下:
- 初始化,标记所有 anchor 为负样本。
- 对于一个 gt,确定其中心落在哪个 cell,计算该 cell 的所有 anchor 与这个 gt 的 iou,取最大值,这个 anchor 标记为正样本,负责预测该 gt。这一步计算 iou 时只考虑形状,不考虑框的位置。具体做法就是将 anchor 和 gt 这两个框的左上角对齐,然后计算 iou。这一步还隐含一个假设,多个 gt 不会落到同一个 cell 中。
- 如果一个 anchor 经过 1 被标记为负样本,但是其与某个 gt 的 iou 大于某个阈值(0.6),则将其标记为忽略(低质量的负样本)。这里需要注意,yolo v2/v3 中这一步计算使用的是 anchor 预测值,而不是预设的 anchor。
区分了正负样本之后就可以用于计算 loss 了,类似 faster-rcnn。
我参考了这篇YOLOv2原理与实现,上述原理在代码中实现是倒过来的,同时在开始时还有计算 predict 和 anchor 的位置偏移,这个能够加快 predict 的形状向 anchor 的形状收敛。因为 yolo 中的 anchor 是聚合而来,本身就比较合理。仔细看下面的 loss 计算公式:
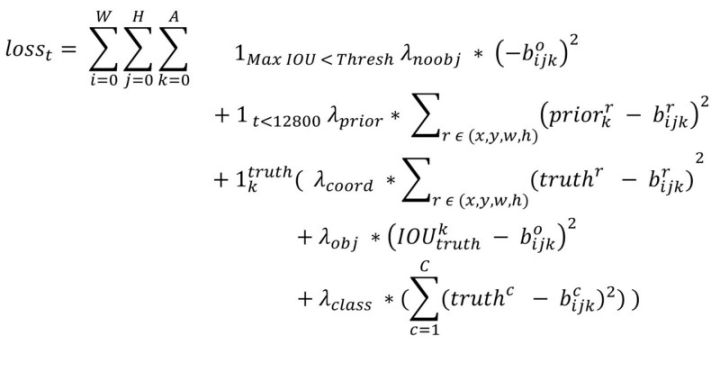
- 求和公式中 W H A 分别表示 feature map 的长、宽以及每个 cell 的 anchor 数量。
- 第一项是负样本,只计算 objectness 的置信度误差。
- 第二项是 anchor 先验框和预测框的坐标误差,只计算前 12800 个迭代,加速预测框向先验框的收敛。
- 第三项是正样本,其中又包含三项:
- 第一项是预测框与 gt 的坐标误差(coord);
- 第二项是是 objectness 置信度误差(obj);
- 第三项是分类误差。
上述公式弄明白了,也就基本理解了各种框的用途和意义了。v3 和 v2 一样是基于 max iou 的匹配规则,只不过有多个检测分支,其规定一个 gt 不可能出现在多个检测分支上,也就是每个 gt 取三个检测分支上 anchor 匹配最大的那个。
YOLO V5
yolo v5 相对 v2/v3 变动很大,主要是匹配规则变了,首先明确一点,v5 和 v3 一样,同样有 3 个检测分支,但是v5 中的匹配是逐层进行的,每一层互不影响,也就是说一个 gt 可以与多个检测层的 anchor 匹配。具体规则如下(以下规则是逐层进行的):
- 对于一个 gt,计算其与当前层的 anchor 是否匹配,匹配是通过 shape 而不是 iou。以 h 为例,就是 gt_h/anchor_h 要大于一个 1/anchor_t,小于 anchor_t,anchor_t 默认设置为 4.0。w 同理。如果不匹配,则说明该 gt 和 anchor 匹配度不够,在当前层的检测中舍弃掉这个 gt。因此在检测小目标的 detect 层,比如下采样为 8 的 P3 层,一个大目标 gt 可能会被舍弃,认为是背景。
- 对于剩余 gt,计算其中心落在哪个 cell 中,同时利用四舍五入方法,找出最近的两个 cell,认为这 3 个 cell 都负责预测这个 gt。很明显,通过这种方法,正样本的数量将明显增多。
- 一个 cell 相邻的有上下左右 4 个cell,根据中心点在当前 cell 中的偏移来找出和中心点比较近的两个相邻 cell。
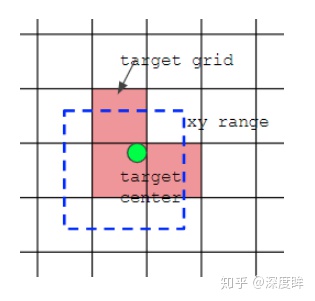
代码中的具体做法是:在任何一预测层,将每个 gt 复制和 anchor 个数一样多的数目(3个),然后将 gt 和 anchor 一一对应计算,去除本层不匹配的 gt,然后对 gt 原始中心点网格坐标扩展两个邻居像素,因此每个 gt 总共有 3 个 cell 上的若干个 anchor 负责预测。有个细节需要注意,前面 shape 过滤时候是不考虑 xy 坐标的,也就是说 gt 的 wh 是和所有 anchor 匹配的,会导致找到的邻居也相当于进行了 shape 过滤规则。详见 build_targets 函数,可以参考解析:yolov5深度可视化解析 。
yolo v5 的改动造成的变化主要如下:
- 不同于 yolov3 和 v4,其 gt 可以跨层预测,即有些 gt 在多个预测层都算正样本。
- 不同于 yolov3 和 v4,其 gt 匹配数范围扩大,明显增加了很多正样本。(但是引入了很多低质量的负样本)
- 不同于 yolov3 和 v4,有些 gt 由于和 anchor 匹配度不高,而变成背景。
有了正负样本,v5 的 loss 计算也很简单,classification 和 objectness confidence 分支都是 bce loss,bbox regression 直接采用 giou loss。