旷视在 2019 年 3 月 推出了 ThunderNet,致力于实现移动端的实时的 two-stage 目标检测器。
实时目标检测的问题与思路
问题
- two-stage detector 的 detection part(Faster R-CNN 中的 Fast R-CNN)过重(一般的head都超过10G FLOPs),即使是 light head R-CNN 也是 head 的计算比 backbone 要高出不少。这种不平衡一方面会造成算力需求过高,另一方面会导致过拟合。
- one-stage detector 由于同时预测 bbox 和类别概率,因此计算开销小;但是由于缺乏 ROI-wise 的特征提取和识别,导致提取的特征比较粗糙,预测精度不高。
如果能够将 two-stage detector 的 backbone 和 prediction head 轻量化,就可能将 two-stage detector 的检测效率提升到足以满足实时性的需求的水平。
思路
- 结合 DetNet 的经验,以 ShuffleNet V2 轻量化骨架为蓝本针对检测任务的特性设计了 SNet 网络作为检测骨架。
- detection 部分则是对 RPN 网络和 prediction head 进行了压缩,同时为了弥补压缩带来的网络表现力的损失引入了 context enhancement module 结合局部和全局特征来提高特征层的表达能力和 spatial attention module 引入 RPN 的前后景信息优化特征的分布。
网络结构
ThunderNet 的网络结构如下图所示:
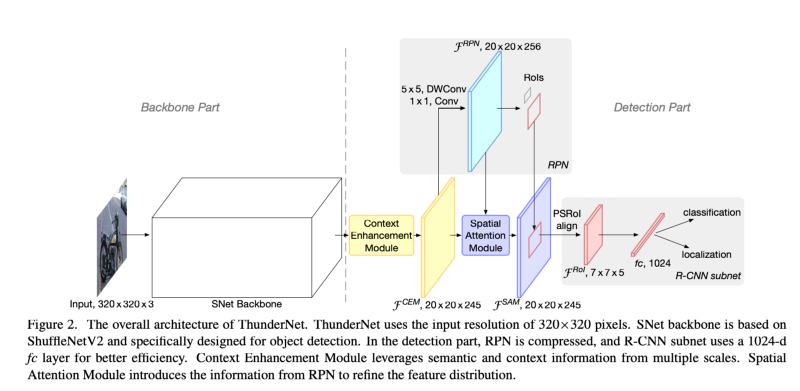
backbone
对检测任务来说,backbone 的感受野大小和对 early stage 及 later stage feature 影响很大:
- 感受野越大可以包含更多上下文信息,这对定位尤其重要,特别是大目标物体的检测;
- early stage feature 包含更多空间信息,对定位影响更大;
- later stage feature 则辨识性更好,对分类影响更大。
对之前的轻量骨架分析发现:ShuffleNet V1/V2 的感受野太小(121/320 pixel); ShuffleNet V2 和 MobileNet V2 则是缺失了 early stage feature。因此作者将 Shufflenet V2 做了修改作为 backbone,命名为 SNet。
SNet
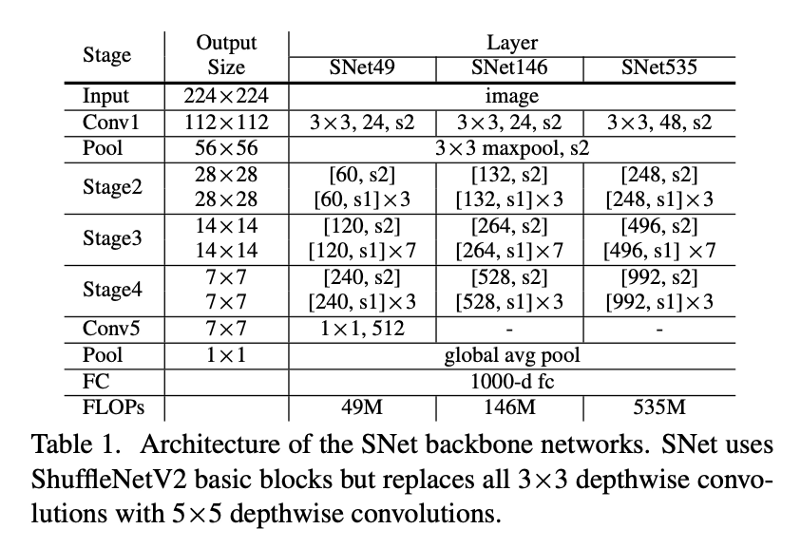
SNet 与 ShuffleNet V2 的不同之处主要在于:
- 为了获得更大的感受野,SNet 中将 ShuffleNet V2 中所有 3x3 depthwise 卷积替换成了 5x5 depthwise(感受野从 121 pixel 增加到 193pixel);
- SNet49 为了更快的速度,将 conv5 中输出的 1024 维压缩到了 512 维(作者认为直接去除 conv5 会导致信息的损失,而保留原来的 1024 维的话则会陷入低级特征)。SNet535 和 SNet146 则是移除 Conv5,在早期的 stage 中增加 channel 数。

压缩 RPN 和 detection head
对于 SNet 来说,现有的 RPN 和 detection head 太重了,因此作者在 light head R-CNN 的基础上将 RPN 的 256 通道 3x3 卷积替换成了 5x5 depthwise + 256 通道 1x1 卷积(计算量下降 28% 但是精度几乎没影响)。anchor 生成包含5种大小(32²,64²,128²,256²,512²)和 5 种长宽比(1:2,3:4,1:1,4:3,2:1)。此外使用 PSRoI align 进行 RoI warping,并且将输出的 channel 从 10 削减一半到 5,输出 feature map 尺寸为 7x7x5;而 PSRoI align 之后的输出只有 245d(7x7x5),因此再添加一个 1024d 的 fc。
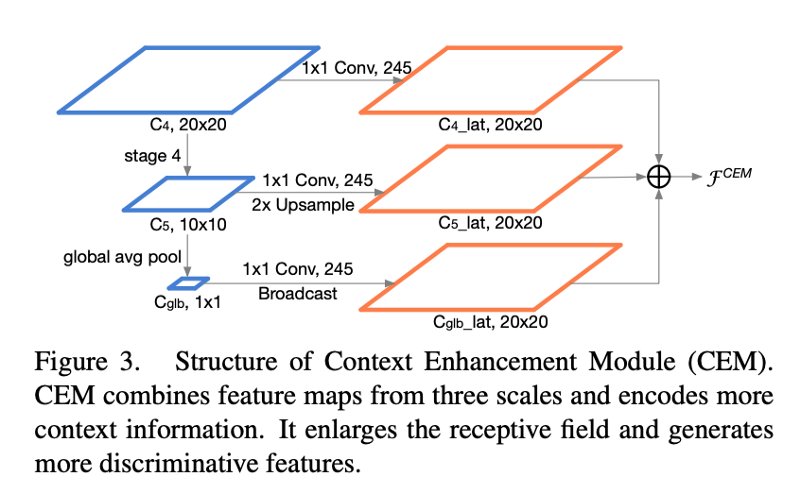
Context enhancement module(CEM)
CEM 可以看做是一个简单的单层 FPN:即将多尺度的局部特征和全局特征进行整合。在 CEM 中合并的特征层为 C4,C5 和 Cglb,并且是由1x1卷积调整输出 channel 到 245,计算开销小。
Spatial Attention Module (SAM)
在 RoI warping 中我们期望前景的特征很强而背景的特征很弱。对于轻量网络和小输入,这个特征分布的学习就会更加困难。因此作者设计了 SAM 在 RoI warping 之前来重新 weight 特征图的分布。其核心思想是由于 RPN 是训练用来识别前景区域,因此 RPN 的中间特征可以用来区分前景特征和背景特征,因此 SAM 引入 RPN 的信息来重新优化前后景的特征分布。
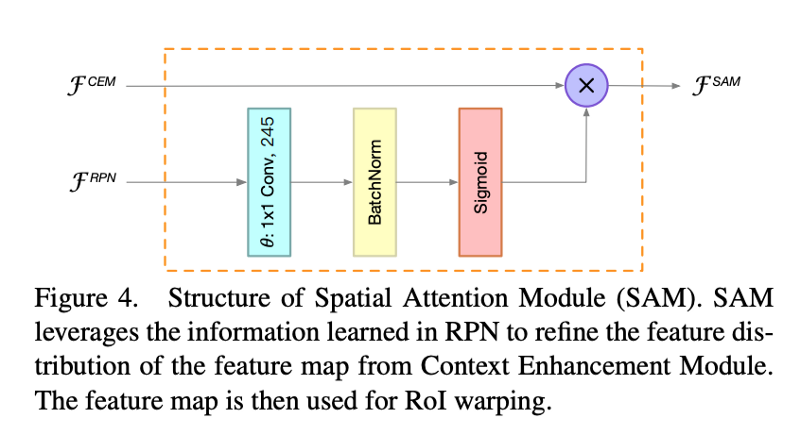
特征计算公式为:
$\theta$ 函数用 1x1 卷积进行维度匹配;sigmoid 函数用于限制值到 [0, 1],然后 $F^{CEM}$ 重新weight 的特征分布。
下图为使用SAM对特征分布的优化效果:

实验结果
效果很不错,具体参见原文吧,懒得贴图了。