Batch Normalization,简称 BN,来源于《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》这篇论文。BN 对于深度学习领域是突破性的成果,直接改善了网络设计和训练的很多缺点,我认为有必要深入学习。我觉得可以从由浅入深好好说一说 BN 的由来的。
Feature Scaling
特征缩放(feature scaling)是机器学习中非常重要的一个预处理。因为数据来源于自然界和人类社会,数据的数值必然有大有小,范围分布都不一致,虽然可以通过机器学习到不同大小的权重和偏差来纠正数据,最终拟合,但是学习的周期变长,甚至因此走入过拟合等不归路,因此将数据规范化是非常重要的一个处理步骤。特征缩放就是为了将数据规范化。一般来说都是将其做均值为 0,方差为 1 的标准化处理,这样能加速模型的收敛。
这是一个具有两个特征的算法学习示意图。
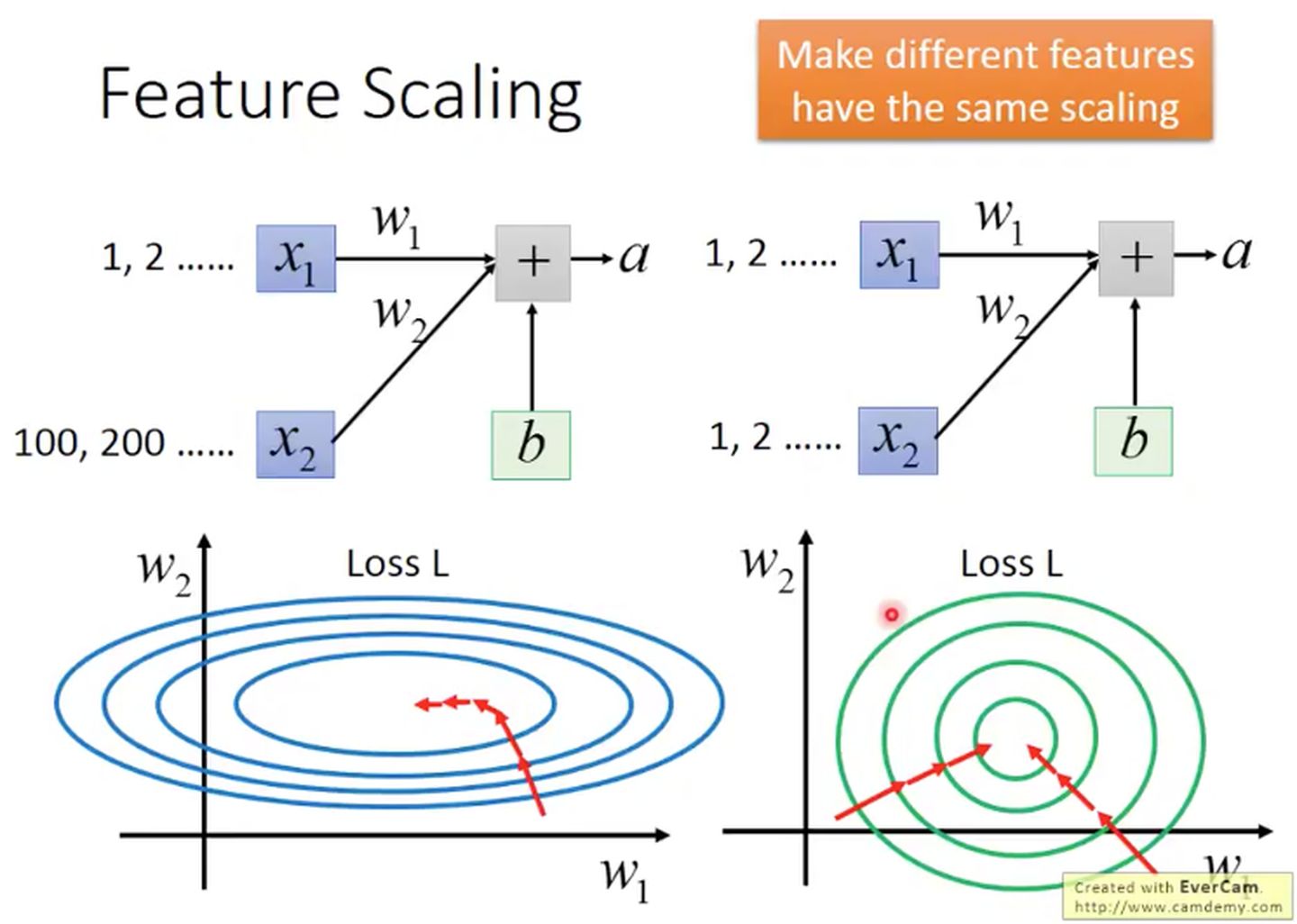
上图很好的反应了特征缩放的好处。左边是原始数据,学习的时候 loss 是范围极广,不同特征分布不均匀,我们必须使用很小的学习率小心的更新参数(因为一个特征的数据非常敏感,数值比较大,对结果影响大,所以在不同方向上梯度不一样)。反之,右边经过特征缩放,数值已经标准化了,所有方向上梯度都一样,因此很快就完成了学习,迅速收敛。
Internal Covariate Shift
在深度学习中,由于问题的复杂性,我们往往会使用较深层数的网络进行训练。在这个过程中,我们需要去尝试不同的学习率、初始化参数方法(例如 Xavier 初始化)等方式来帮助我们的模型加速收敛。深度神经网络之所以如此难训练,其中一个重要原因就是网络中层与层之间存在高度的关联性与耦合性。
网络中层与层之间的关联性会导致如下的状况:随着训练的进行,网络中的参数也随着梯度下降在不停更新。一方面,当底层网络中参数发生微弱变化时,由于每一层中的线性变换与非线性激活映射,这些微弱变化随着网络层数的加深而被放大(类似蝴蝶效应);另一方面,参数的变化导致每一层的输入分布会发生改变,进而上层的网络需要不停地去适应这些分布变化,使得我们的模型训练变得困难。上述这一现象叫做 Internal Covariate Shift。
同时随着网络加深的还有反向传播的梯度消失问题,这个问题通过 ResNet 的残差连接解决。
什么是 Internal Covariate Shift?
Batch Normalization 的原论文作者给了 Internal Covariate Shift 一个较规范的定义:在深层网络训练的过程中,由于网络中参数变化而引起内部结点数据分布发生变化的这一过程被称作Internal Covariate Shift。
这个概念简单的理解就是 w 和 b 都在更新,导致激活层的输入也在不断改变,进而激活层的输出也会发生变化。而前一层激活层的输出变化进一步导致后一层的输入数据分布发生改变,说白了就是每一层的输入数据分布都因为学习到新的 w 和 b 而发生变化。
Internal Covariate Shift 会带来什么问题?
- 上层网络需要不停调整来适应输入数据分布的变化,导致网络学习速度的降低。
- 网络的训练过程容易陷入梯度饱和区,减缓网络收敛速度。
- 如果网络使用饱和激活函数,比如 sigmoid,但 w 和 b 不断增大,那么最终进入激活函数的梯度饱和区(变化不大的区域),网络更新速度减慢,拖累收敛。
- 解决方法的思路一方面可以使用非饱和激活函数,比如 ReLU。另一方面可以让激活函数输入分布保持在非梯度饱和区,也就是 normalization。
如何缓解 Internal Covariate Shift
Internal Covariate Shift 产生的原因是每一层输入数据不断的变化,那么缓解的方法自然就是限制每一层输入数据的分布,让其不再剧烈变化甚至同分布。这自然就想到了数据规范化。数据归一化的方式有很多,比如 PCA 白化等等。但是由于计算成本以及保留原始数据的信息表达能力(这个也很重要)等原因,作者使用 batch normalization 这种方式。
Batch Normalization
思路很简单,就是对深度神经网络中每个层逐通道的做 normalization。比如输入的 blob 是 (N,C,H,W),每个 normalization 参与的数据数量就是 N*H*W。
Batch Normalization 的算法思路如下:

规范化计算很简单:
- 计算参与规范化的数据的均值
- 计算参与规范化的数据的反差
- 每个数据减均值,除方差(引入一个极小值防止除零)。
BN 中有减均值操作,所以要使用 BN 的层不需要再使用偏置项了。
最初版本的 BN 大概就是这么简单,但是作者直接对其做了改进,图中的算法是第二版了,也就是增加了 scale-shift 操作。
直接使用归一化后的数据和 PCA 白化一样,导致数据的表达能力丢失了,主要是上一层传递过来的数据分布信息到本层完全丢失了。另一方面,如果是 sigmoid 或者 tanh 这种激活函数,BN 之后的数据基本都落在了线性区域,那么其非线性区域的功能就丢失了。
关于为什么丢失我觉得可以参考 PCA 白化中数据信息量的讲解,我理解就是数据信息被压缩了。
scale-shift
应该注意到,算法中还有一个 scale-shift 操作,其中包含两个可学习的参数。这两个参数的引入是为了恢复数据本身的表达能力,对规范化后的数据进行线性变换,特别地,当 $\gamma = \sigma ^2, \beta = \mu$ 时,可以实现等价变换(identity transform)并且保留了原始输入特征的分布信息。
这里的意思就是输入的数据本身不是归一化的,我们使用了归一化之后,数据是规范了,但是数据本身的特性丢失了,因此加缩放和偏移来近似表示这部分信息。
原文的意思大概就是锦上添花。通过 scale-shift 操作加入一些可缩放的自由度,从而没那么僵硬导致信息丢失。scale-shift 在训练和测试的时候都执行,其参数通过反向传播更新学习。
测试阶段如何使用 Batch Normalization?
我们知道 BN 在每一层计算的 $\mu$ 与 $\sigma ^2$ 都是基于当前 mini-batch 中的训练数据,但是这就带来了一个问题:我们在预测阶段,有可能只需要预测一个样本或很少的样本,没有像训练样本中那么多的数据,此时 $\mu$ 与 $\sigma ^2$ 的计算一定是有偏估计,这个时候我们该如何进行计算呢?
BN 训练好模型后,保留每组 mini-batch 训练数据在网络中每一层逐通道的均值和方差,然后求得训练数据整体的均值和方差(每一层,逐通道)。也就是说在测试的时候使用训练数据整体的均值和方差来对测试数据做推理,基于训练数据和测试数据属于统一数据分布的假设,这可以看作是测试数据的无偏估计。
Quora 中有人指出,在 style-transfer 中,在 inference 的时候,使用单张图片直接计算均值和方差效果更好,这应该是其任务比较特殊。
tensorflow 中保存模型的时候不能只保存 trainable_variables,因为 BN 的参数不属于 trainable_variables。为了方便,可以用 global_variables。同理,读取的时候也应该使用 global_variables。