当我们需要开发一门语言时候,不可避免要对词法和语法进行解析。而在工作中,有时候也需要对一些约定的表达式进行分析和求解,这其实和语言中的解释器、编译器的词法语法解析功能很类似。本文根据实习小项目的经历,对利用Antlr进行语法表示式的解析过程做一个简要介绍。
对于一种语言或者说表达式的处理,一般处理工作都分为前端和后端两个部分:
- 前端进行词法分析、语法分析、语义分析、中间代码生成等若干步骤
- 后端进行代码优化、表达式求解等处理
而借用Antlr这个工具,我们可以很方便的实现语法和词法解析,也就是前端工作。
1. Antlr 简介
Antlr 是一种语言识别工具,和 Lex 以及 YACC 等工具类似,通过上下文无关的文法来对表达式的词法和语法进行描述,而且能够自动生成词法分析器 (Lexer)、语法分析器 (Parser) 和树分析器 (Tree Parser)。
Antlr 致力于解决编译前端的所有工作。使用 Anltr 的语法可以定义目标语言的词法记号和语法规则,Antlr 自动生成目标语言的词法分析器和语法分析器;此外,如果在语法规则中指定抽象语法树的规则,在生成语法分析器的同时,Antlr 还能够生成抽象语法树;最终使用树分析器遍历抽象语法树,完成语义分析和中间代码生成。整个工作在 Anltr 强大的支持下,将变得非常轻松和愉快。
对于词法和语法的定义,Antlr使用正则表达式完成匹配工作,编辑工作很轻松。
配置Antlr
对于Antlr开发java项目,可以使用 Eclipse 和 Intellij 插件,插件具有语法高亮和 Antlr 规则测试等很便捷的功能。Antlr 本身是使用 Java 开发的,在使用 Antlr 之前必须先安装 JRE(Java Runtime Environment )。这里附 Intellij 的 Antlr 插件地址:
对于实际导入 Antlr 的库,可以在maven中直接配置依赖,不再详述。
2. Antlr 使用
创建一个 Antlr 文件,最新的 Antlr V4 版本,使用 g4 作为后缀名,例如:Eval.g4。
文件开头定义文法的名字:
1 | grammar Eval; |
需要注意的是,文法名字必须和文件名相同。(这一点和java倒是有点像…)
在 Antlr 文件中,词法规则和语法规则由下向上书写,构成一个抽象的语法树,而在每一个语法规则中,算法的优先级也遵循嵌套定义的规则,优先级由下至上递增。
每个规则的定义有自己的定义符号,定义符号和规则语法用 : 隔开,以 ; 结尾,并通过 | 等实现多项匹配。语法和词法定义的区别通过定义符号的大小写来区别。规定:
- 语法规则定义符号的第一个字母小写(实际整个符号通常都是小写)
- 词法规则定义符号的第一个字母大写(实际整个符号通常都是大写)
还可以自定义对于空格符以及换行等相应的处理办法。Antlr 支持多种目标语言,可以把生成的分析器生成为 Java,C#,C,Python,JavaScript 等多种语言,默认目标语言为 Java,通过 options {language=?;} 来改变目标语言。而对于词法和语法的定义,一般都会有一些黄金定律之类的,可以根据实际项目需求来编写。这里给出一个较为详细的中文版Antlr文法规则,可供参考。
下面是一个简单的算术表达式的定义举例:
1 | grammar Eval; |
(fragment 是词法定义的特殊格式,表示是词法构成的一部分,非完整的词法规则)
编辑完 Antlr 文件后,我们在安装有 Antlr plugin 的 Intellij 上,可以通过右键语法规则对语法规则进行测试,并可以在配置生成中间代码的包名、路径等选项后,直接生成中间代码。
对于生成的中间代码,一般都会得到6个文件:
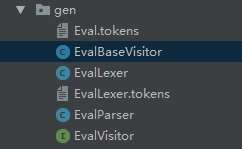
- Eval.tokens和EvalLexver.tokens 为文法中用到的各种符号做了数字化编号
- EvalLexer.java 是词法分析器
- EvalParser.java 是语法分析器
- EvalVisitor 和 EvalBaseVisitor 分别是语法解析树的vistor的接口和类,用于遍历整个语法树。一般情况下,我们通过继承 EvalBaseVisitor 来实现自己对于语法树遍历的处理。
至此,Antlr部分就全部完成,接下来就是编写自己的 Visitor。
3. 后端处理
当编写自己的 Visitor 时,需要有一个较好的思路去设计对于解析语法树流程中的处理策略。EvalBaseVisitor 类中自动生成了遍历每一个语法规则的函数,因为我自身对 java 了解甚少,在参考了前辈的设计基础上,设计了相对简单的策略:
- 对于每一种类型的表达式,设计一个相应的类来表示,这些类共同实现一个表达式接口。
- 在接口中,定义了表达式必要的求解方法,也就是如何计算表达式的值,每种表达式应该有自己的求解方法。
- 遍历每一个语法规则时,根据语法,构造对应的表达式的对象(本质上可以用工厂模式来实现)
下面是一个对于二元运算规则处理的简单示例:
- 表达式接口:
1 | public interface IExpr { |
- 二元计算表达式
1 | public class BinaryExpr implements IExpr { |
- Vistor中的遍历处理
1 | public IExpr visitExpr(EvalParser.BinaryExprContext ctx) { |
当定义完这些后端处理的方法之后,我们可以调用用Antlr库中的词法分析和语法分析类对输入的表达式进行解析得到表达式的语法树,然后遍历语法树,并对表达式对象进行递归求解,从而获得表达式的解。调用代码如下:
1 | public Object run(String expr, Map<String, Object> varMap) { |
于是就得到了整个表达式的结果。对于复杂的表达式,我们从 Antlr 文法定义中就可以看出,本质上是简单表达式不断构建而成,在 Visitor 中,我们可以通过递归的方式进行语法树遍历,而我们只要处理基本表达式就行了。
后记
本文简要介绍了java中解析表达式的工具Antlr使用。利用Antlr可以很方便的进行词法和语法解析,配合后端处理,完成对于自定义表达式的求解规则定义。
本文的例子相对简单,主要目的在于介绍基本用法,整个解析流程以及后端的处理策略。实际项目中,表达式不可能这么简单,特别是涉及到函数的调用方面,不仅需要利用反射进行函数的注册,还需要进行严格的参数类型匹配和转换。而对于一些长时操作求解的赋值表达,可能还会涉及延时计算等手段来提升效率等等,而且很对处理策略需要在实际项目中填坑才能体会到,所以就不展开赘述了。