本文详细讲解大模型 RLHF 阶段使用的 PPO(Proximal Policy Optimization)训练原理和实现细节。我们将从强化学习基础概念开始,逐步深入到 PPO 在 LLM 中的具体应用,最后分析 PPO 的损失函数和优势估计计算。
1. 强化学习基础
1.1 什么是强化学习
强化学习(Reinforcement Learning, RL)是机器学习的一个分支,区别于监督学习和无监督学习。其核心特点是:
- 无标签学习:没有预定义的正确答案,而是通过试错和奖励来学习
- 与环境交互:智能体通过与环境的交互来获取反馈信号
- 延迟反馈:奖励可能是延迟的,需要考虑长期累积回报而不仅是即时奖励
- 自我改进:根据奖励信号不断优化决策策略
1.2 强化学习的核心要素
强化学习框架包含两个主要实体:智能体(Agent)和环境(Environment),两者通过以下要素进行交互:
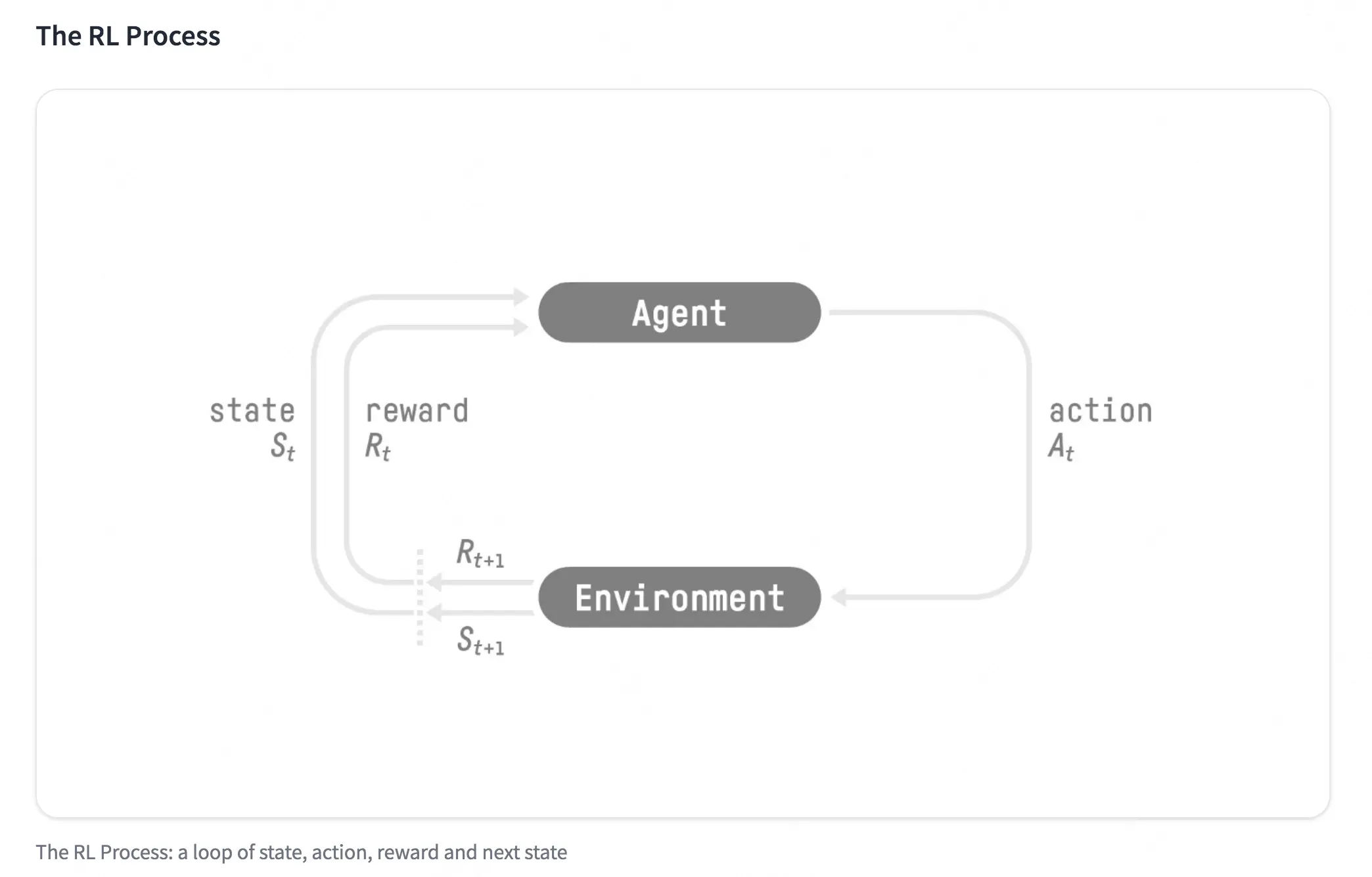
核心概念:
- 状态(State)$s_t$:智能体在时刻 $t$ 观测到的环境状态
- 动作(Action)$a_t$:智能体选择执行的动作,属于动作空间 $\mathcal{A}$
- 奖励(Reward)$r_t$:智能体执行动作后从环境获得的即时反馈
- 策略(Policy)$\pi(a|s)$:智能体的决策函数,定义在给定状态下选择动作的概率
- 轨迹(Trajectory)$\tau$:状态-动作-奖励序列 $(s_0, a_0, r_0, s_1, a_1, r_1, \ldots)$
1.3 交互过程
一个完整的强化学习交互循环如下:
- 智能体在状态 $s_t$ 下,根据策略 $\pi$ 选择动作 $a_t$
- 环境根据动作 $at$ 转移到新状态 $s{t+1}$,并返回奖励 $r_t$
- 智能体根据获得的 $(st, a_t, r_t, s{t+1})$ 四元组来更新策略
- 重复上述过程,不断优化策略
根本目标:找到最优策略 $\pi^*$,使得智能体根据环境状态选择的动作能最大化长期累积奖励。
数学上,累积奖励定义为:
其中 $\gamma \in [0,1]$ 是折扣因子,用于平衡即时奖励和未来奖励的重要性。
1.4 策略梯度定理
策略梯度定理是强化学习中的核心理论基础,为 PPO 算法提供了数学基础。
目标函数
在强化学习中,我们的目标是最大化期望累积奖励。对于策略 $\pi_\theta$(由参数 $\theta$ 参数化),目标函数定义为:
其中:
- $\tau$ 是轨迹(状态-动作-奖励序列)
- $R(\tau)$ 是轨迹 $\tau$ 的累积奖励
- $\mathbb{E}{\tau \sim \pi\theta}$ 表示在策略 $\pi_\theta$ 下的期望
策略梯度定理的核心内容
策略梯度定理告诉我们如何通过梯度上升来优化策略参数 $\theta$,以最大化目标函数 $J(\theta)$。具体地:
公式含义:
- 左侧:目标函数 $J(\theta)$ 关于参数 $\theta$ 的梯度,指示参数如何变化才能增加期望奖励
- 右侧:策略对数概率的梯度与轨迹奖励的乘积的期望
直观理解:
- 如果轨迹 $\tau$ 的奖励 $R(\tau)$ 较高,我们就增加这个轨迹的概率
- 如果轨迹 $\tau$ 的奖励 $R(\tau)$ 较低,我们就减少这个轨迹的概率
- $\nabla\theta \log \pi\theta(\tau)$ 指示在参数空间中应该朝哪个方向移动
策略梯度方法的局限性
虽然策略梯度定理提供了优化框架,但直接应用存在几个严重问题:
- 高方差:直接使用轨迹奖励会导致方差很大,训练不稳定
- 样本效率低:需要大量样本才能准确估计期望,导致采样成本高
- 学习信号稀疏:对于长轨迹,只有轨迹末端的奖励,无法有效指导中间步骤的学习
- 更新步长难控:策略更新幅度可能过大,导致学习不稳定甚至发散
这些问题激发了 PPO 等改进算法的发展。
1.5 PPO 算法的核心思想
PPO(Proximal Policy Optimization)通过引入重要性采样比率(Importance Sampling Ratio) 来限制策略更新的幅度,在保证训练稳定性的同时提高样本效率。
重要性采样比率
PPO 定义的重要性采样比率为:
比率含义:
- $\pi{\theta{old}}(a_t|s_t)$:旧策略(更新前)在状态 $s_t$ 下选择动作 $a_t$ 的概率
- $\pi_\theta(a_t|s_t)$:新策略(更新后)在状态 $s_t$ 下选择动作 $a_t$ 的概率
- $r_t(\theta)$:新策略相对于旧策略的概率变化比例
为什么需要限制策略更新幅度
- 防止策略崩溃:过大的更新可能导致某些动作概率变为 0,失去探索能力,或导致策略完全改变而偏离原有轨道
- 保证训练稳定性:过大的更新步长会导致目标函数振荡甚至发散
- 避免灾难性遗忘:过度更新会使新策略完全偏离旧策略,丢失之前学到的有用知识
PPO 的裁剪机制
PPO 的主要创新是引入了裁剪机制来限制更新幅度:
裁剪函数定义:
核心机制:
当优势函数 $A_t > 0$(表示这是一个好的动作)时:
- 如果 $r_t(\theta) < 1$(新策略概率较小),鼓励增加动作概率,但最多只能增加到 $1+\epsilon$ 倍
- 如果 $r_t(\theta) > 1+\epsilon$(新策略概率已经足够大),停止鼓励,避免过度优化
当优势函数 $A_t < 0$(表示这是一个坏的动作)时:
- 如果 $r_t(\theta) > 1$(新策略概率较大),鼓励减少动作概率,但最多只能减少到 $1-\epsilon$ 倍
- 如果 $r_t(\theta) < 1-\epsilon$(新策略概率已经足够小),停止惩罚,避免过度惩罚
参数说明:
- $A_t$:优势函数(衡量动作相对于平均水平的优势)
- $\epsilon$:裁剪范围,通常设置为 0.2,意味着策略更新幅度被限制在 ±20% 以内
- 这个设计确保了策略不会偏离过远,同时充分利用有利的轨迹进行学习
1.6 价值函数
为什么需要价值函数
在策略梯度方法中,我们使用轨迹的累积奖励 $R(\tau)$ 来更新策略。但这个方法存在一个问题:方差很大。
对于一条长轨迹,很多步骤都会获得同样的奖励信号(终点的奖励),这会导致许多中间步骤的梯度估计方差很高,学习效率低。
为了解决这个问题,我们引入价值函数(Value Function) 的概念:价值函数预测从某个状态开始能获得的期望累积奖励,可以作为”基线”来减少方差。
状态价值函数
状态价值函数 $V(s_t)$ 定义为:从状态 $s_t$ 开始,遵循策略 $\pi$ 能获得的期望累积奖励。
关键特点:
- 仅依赖于状态,与具体的动作无关
- 表示该状态的”好坏程度”(价值)
- 在 LLM 中,Critic 模型就是用来估计 $V(s_t)$ 的
动作价值函数
动作价值函数 $Q(s_t, a_t)$ 定义为:在状态 $s_t$ 下采取动作 $a_t$,然后遵循策略 $\pi$ 能获得的期望累积奖励。
关键特点:
- 依赖于状态和具体的动作
- 表示在特定状态下采取特定动作的”好坏程度”
- 可以用来评估一个动作相对于其他动作的相对优势
两种价值函数的关系
状态价值函数是动作价值函数在所有可能动作上的期望:
这个关系说明:某个状态的价值等于在该状态下遵循策略选择所有可能动作的期望价值。
1.7 优势函数
概念定义
优势函数(Advantage Function)衡量了在某个状态下采取某个特定动作相对于该状态平均水平的优势程度。它是 PPO 算法中最重要的概念之一。
核心含义:
优势函数的直观理解
- 如果 $A_t > 0$:表示动作 $a_t$ 比该状态的平均水平更好,应该增加这个动作的概率
- 如果 $A_t < 0$:表示动作 $a_t$ 比该状态的平均水平更差,应该减少这个动作的概率
- 如果 $A_t \approx 0$:表示动作 $a_t$ 处于平均水平,既不特别好也不特别差
优势函数的优势(为什么用它)
与直接使用奖励相比,优势函数有几个重要优势:
- 减少方差:相比使用原始奖励,优势函数通过相对比较而不是绝对值,大大降低了学习信号的方差,使训练更稳定
- 有效的基线:状态价值函数 $V(s_t)$ 作为基线(baseline),消除了与动作选择无关的状态价值部分,让梯度只关注动作的相对优劣
- 更细粒度的反馈:在同一状态下,优势函数能清晰区分不同动作的相对好坏,提供更精确的学习信号
- 加速收敛:相对比较的学习信号更容易指导策略优化,使训练收敛速度更快
时序差分估计
在实践中,我们通常使用时序差分(Temporal Difference, TD) 方法来估计优势函数。最简单的 TD(0) 估计为:
这个公式的含义是:
- $rt + \gamma V(s{t+1})$:实际观测到的短期收益加上对未来的价值估计
- $V(s_t)$:模型原本对该状态价值的预期
- 它们的差异就是”surprise”,即实际与预期的偏差
2. LLM 中的强化学习应用
现在我们已经理解了强化学习和 PPO 的基本原理,接下来看看如何将这些理论应用到 LLM 的训练中。
2.1 LLM 的生成过程
LLM 的推理过程遵循自回归范式:给定 prompt,模型逐个生成 token,直到生成完毕。具体过程如下:
- 初始化:输入 prompt,对应 RL 中的初始状态 $s_0$
- 迭代生成:每个时刻 $t$,模型基于当前上下文(状态 $s_t$)产生一个新 token(动作 $a_t$)
- 状态转移:产生的新 token 被添加到上下文中,形成新的上下文作为下一时刻的状态 $s_{t+1}$
- 终止:当生成 EOS(End-of-Sequence)token 或达到最大长度时,生成过程结束
2.2 LLM 生成过程中的 RL 映射
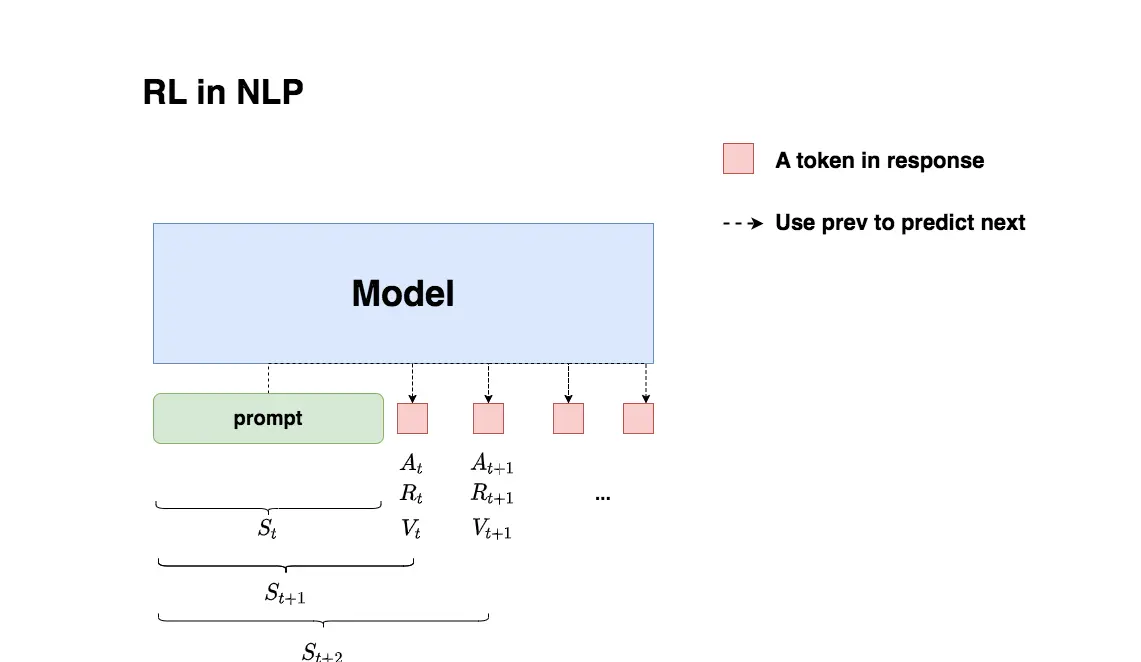
让我们将 LLM 生成过程映射到强化学习框架中:
核心映射:
| RL 概念 | LLM 中的含义 |
|---|---|
| 智能体(Agent) | 语言模型本身 |
| 状态(State)$s_t$ | 当前的输入提示和已生成的 token 序列(上下文) |
| 动作(Action)$a_t$ | 在时刻$t$ 生成的 token(从词汇表中选择) |
| 动作空间 | 词汇表(通常包含数万个 token) |
| 奖励(Reward)$r_t$ | 人类偏好信号(通过奖励模型 RM 评估) |
| 策略(Policy)$\pi$ | 模型的概率分布输出$P(a_t \mid s_t)$ |
关键区别:
- 在 RL 中,每一步都可能获得奖励;在 LLM 中,奖励通常是稀疏的,只在序列生成完成时才获得一个标量奖励
- 这个差异导致 LLM 中的 RLHF 需要特殊的奖励设计和处理
2.3 RLHF 训练的必要性
为什么需要用 RLHF 进行后训练呢?
偏离 SFT 目标:SFT(Supervised Fine-Tuning)阶段使用人工标注的高质量回答来训练,但这种方法:
- 数据成本高昂(需要大量人工标注)
- 无法很好地优化人类真实的、多样化的偏好
- 无法直接优化人类偏好:SFT 是模仿学习,模型学到的是”如何模仿”而不是”如何做得好”
- 奖励函数设计困难:不同的应用场景对 LLM 的要求不同,需要灵活的奖励机制来指导模型朝着特定目标优化
- 充分发挥模型能力:RLHF 能让已有的语言模型进一步优化,使其生成更符合人类偏好的回答
3. RLHF 中的模型架构
在 PPO 阶段的 RLHF 训练中,需要协调多个模型来共同完成优化目标。这一节我们详细介绍这些模型及其作用。
3.1 四个核心模型
RLHF 中的 PPO 训练涉及 4 个不同的模型,它们各司其职:
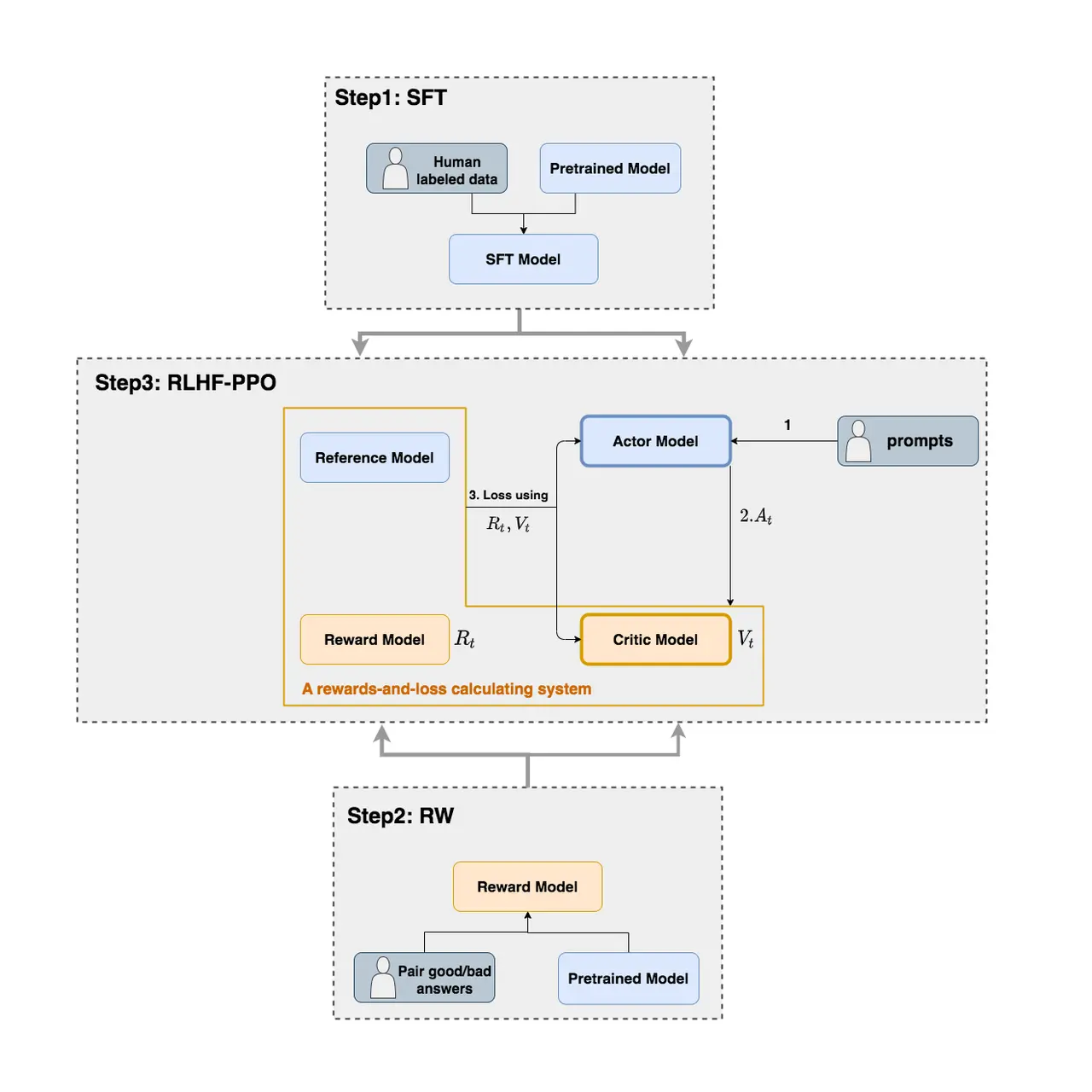
| 模型 | 全称 | 作用 | 参数更新 |
|---|---|---|---|
| Actor | Actor Model | 生成回答的策略模型,最终部署的模型 | ✓ 需要 |
| Critic | Critic Model | 评估状态价值,估计长期收益 | ✓ 需要 |
| Reward Model | Reward Model | 评分函数,衡量生成回答的整体质量 | ✗ 不需要 |
| Reference | Reference Model | 参考标准,限制 Actor 的偏离程度 | ✗ 不需要 |
3.2 模型详解
Actor Model(策略模型)
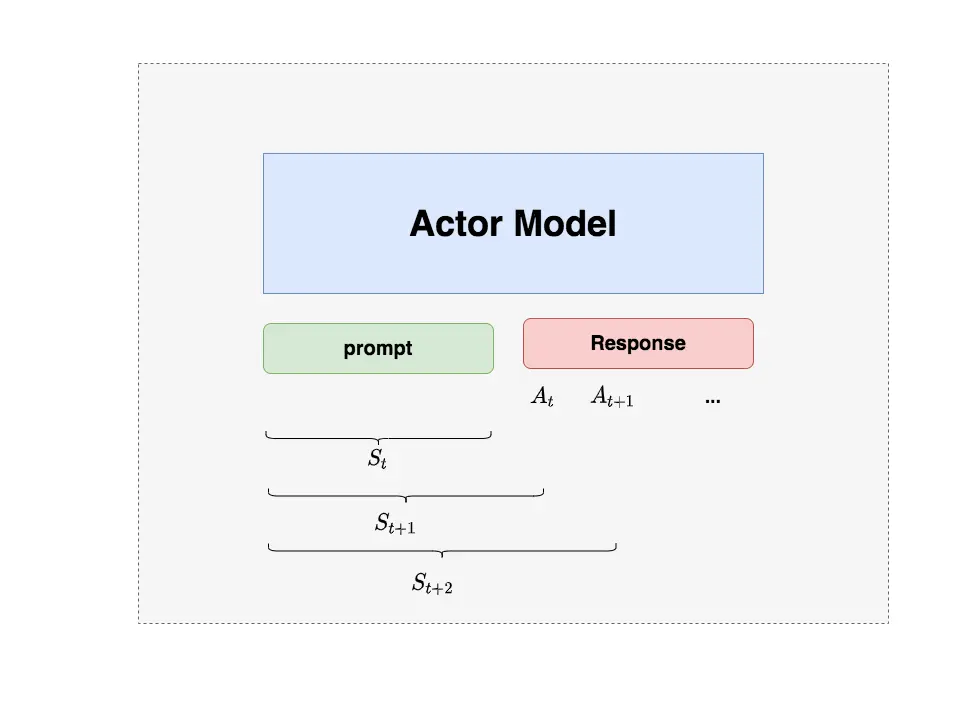
职责:生成符合人类偏好的回答
特点:
- 基于 SFT 模型微调得到,在 PPO 阶段继续优化
- 接收 prompt,生成一系列 token 作为回答
- 是 RLHF 训练的直接对象,参数持续更新
工作流程:
- 给定 prompt 输入
- 模型根据学到的策略逐个生成 token
- 将”prompt + response”送入损失计算体系进行优化
- 通过反向传播更新参数
Reference Model(参考模型)
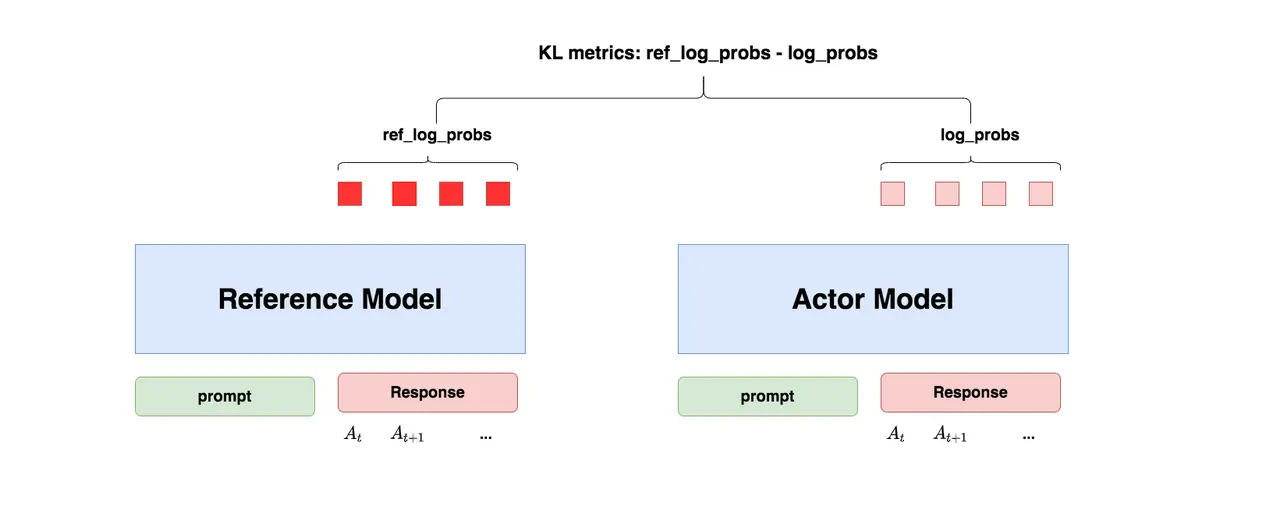
职责:作为优化的约束,防止 Actor 偏离过大
特点:
- 通常用 SFT 模型初始化
- 参数冻结,在整个 RLHF 过程中不更新
- 代表”原始能力基线”
核心机制 - KL 散度约束:
我们希望训练出来的 Actor 既能达到符合人类偏好的目标,又尽量让输出分布与原始 SFT 模型相近。这通过 KL(Kullback-Leibler)散度来衡量:
防止模型训歪的直观理解:
- 如果 Actor 更新使得某些输出的概率变化太大,KL 散度会很高,产生较大的惩罚
- 这种约束防止模型为了追求高奖励而生成虚假、有害或无意义的内容
- 保证模型保留原有的知识和能力
Critic Model(价值模型)
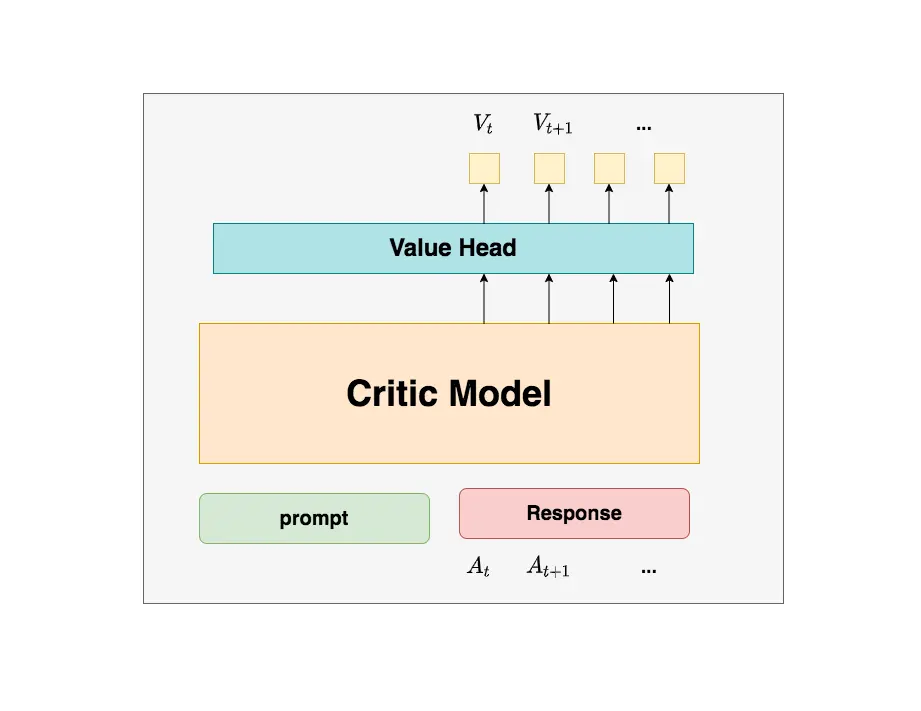
职责:估计状态的长期价值,指导策略优化
特点:
- 架构与 Actor 相似,基于 SFT 模型
- 添加了一个”Value Head”输出层:将最后一个 token 的隐藏状态(通常 4096 维)映射到一个标量值
- 参数需要更新,通过 MSE 损失函数优化
价值头的计算:
1 | 隐藏状态 (d_model,) → 线性层 (1,) → 单一标量价值 V(s_t) |
工作流程:
- 接收相同的 prompt + response 输入
- 在每个 token 位置都可以输出一个价值估计 $V(s_t)$
- 用于计算时序差分 TD 误差和优势函数
- 通过价值函数损失来更新参数
Reward Model(奖励模型)
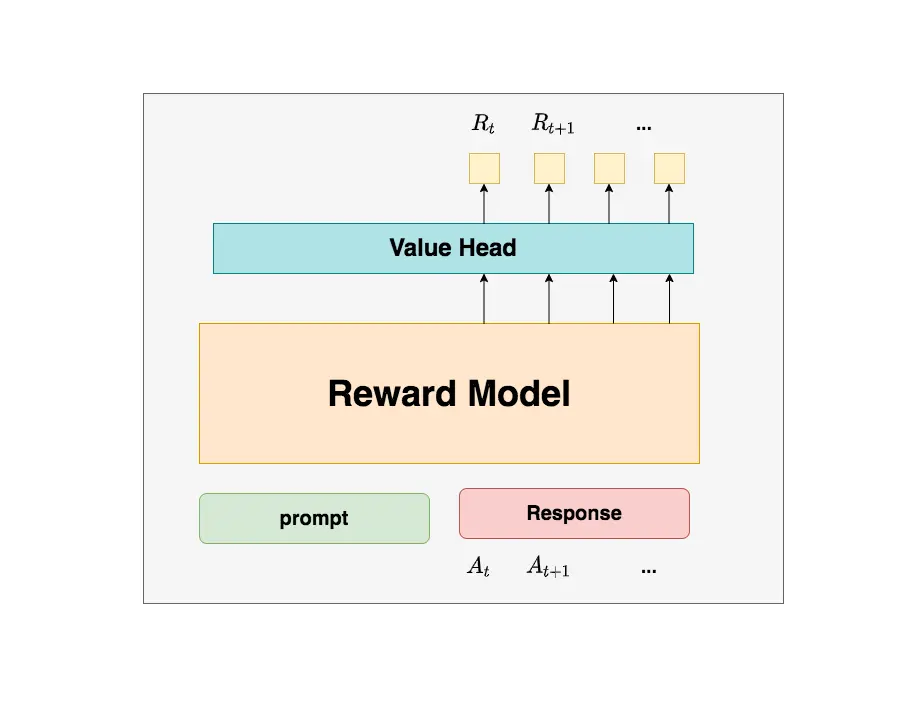
职责:评估整个生成序列的质量
特点:
- 在 RLHF 第一阶段(Reward Modeling 阶段)提前训练好
- 参数冻结,PPO 阶段不更新
- 提供客观的、绝对的评分标准
奖励计算:
- 只在序列生成完成时(EOS token)进行一次评分
- 输出一个标量奖励 $r_{\text{final}}$,代表整个回答的质量
- 不对中间 token 进行评分(奖励是稀疏的)
为什么不更新参数:
- 冻结奖励模型确保评分标准的一致性和客观性
- 如果边训练边更新,会导致奖励标准不断变化,模型学习信号混乱
- 冻结参数保证了训练过程中有一个稳定的、绝对的评估基准
3.3 四个模型的关键区别对比
奖励模型 vs 价值模型:
这是初学者最容易混淆的地方。让我们清晰地对比:
| 维度 | Reward Model | Critic Model |
|---|---|---|
| 评分时机 | 序列结束时(EOS),一次性评分 | 每个 token 位置都有评分 |
| 评分特性 | 稀疏奖励(只在末端) | 密集价值估计(每步都有) |
| 更新 | 冻结不更新 | 需要更新参数 |
| 作用 | 衡量整体质量 | 估计长期收益 |
| 输入 | 完整的 prompt + response | 完整的 prompt + response |
| 评分依据 | 人类偏好信号 | TD 误差和实际奖励 |
| 反向传播 | 无(冻结参数) | 有(通过 Value Loss) |
直观例子:
- RM:就像最终的考官,在你完整答题后给一个分数
- Critic:就像教练,在你的每一步都给出潜在的长期收益评估
4. PPO 损失函数与优化
PPO 的强大之处在于其巧妙的多目标损失函数设计。让我们深入理解 PPO 如何通过损失函数来平衡多个优化目标。
4.1 总体损失函数
PPO 的总损失函数由三部分组成:
其中 $L^{\text{CLIP}}$、$L^{\text{KL}}$、$L^{\text{VF}}$ 分别对应:
重要:这里的 $\mathbb{E}_t$ 表示对所有 token 的期望,即:
也就是说:
- 首先对单个序列内的所有 token 计算损失并求平均
- 然后对 batch 内的所有序列求平均
每一项都对应一个特定的优化目标:
| 损失项 | 来源模型 | 目标 | 权重 |
|---|---|---|---|
| $L^{\text{CLIP}}$ | Actor | 优化策略以最大化奖励 | 1(基准) |
| $L^{\text{KL}}$ | Reference | 限制与参考模型的偏离 | $\alpha$ (通常 0.2) |
| $L^{\text{VF}}$ | Critic | 训练价值函数估计器 | $\beta$ (通常 0.5) |
直观理解:
- Actor 想要尽可能追求高奖励
- Reference 在其肩膀上按住,说”别偏离原来的太远”
- Critic 在旁边学习”这个状态值多少钱”
4.2 策略损失:$L^{\text{CLIP}}$
这是 PPO 的核心创新,我们已经详细讨论过。这里补充一些实现细节。
定义
其中:
- $rt(\theta) = \frac{\pi\theta(at|s_t)}{\pi{\theta_{\text{old}}}(a_t|s_t)}$:Token 级别的重要性采样比率(新策略相对于旧策略的概率比)
- $A_t$:优势估计(也是 token 级别)
- $\epsilon = 0.2$:裁剪范围
关键点:PPO 在每个 token 位置都计算一个重要性采样比率和优势,然后对这些 token 进行 min 和 clip 操作。这与只考虑序列级别的方法不同。
为什么使用 min 操作
PPO 使用 $\min$ 操作和裁剪的巧妙之处:
无裁剪项 $r_t(\theta) A_t$:
- 当 $A_t > 0$ 时,$r_t$ 越大越好(鼓励增加好动作)
- 当 $A_t < 0$ 时,$r_t$ 越小越好(鼓励减少坏动作)
有裁剪项 $\text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) A_t$:
- 强制 $r_t$ 的范围,防止更新过大
$\min$ 操作的作用:
- 当 $A_t > 0$(好动作)时,选择两者中较小的,防止过度优化
- 当 $A_t < 0$(坏动作)时,选择两者中较小的,防止过度惩罚
数值例子:
假设 $\epsilon = 0.2$,$A_t = 1.0$(好动作):
| $r_t(\theta)$ | $r_t A_t$ | $\text{clip}(r_t) A_t$ | $\min$ 结果 | 含义 |
|---|---|---|---|---|
| 1.5 | 1.5 | 1.2 | 1.2 | 已经足够好了,停止优化 |
| 1.3 | 1.3 | 1.2 | 1.2 | 已经足够好了,停止优化 |
| 1.1 | 1.1 | 1.1 | 1.1 | 继续鼓励 |
| 0.9 | 0.9 | 0.9 | 0.9 | 有所衰退,仍需改进 |
| 0.5 | 0.5 | 0.8 | 0.5 | 已经太差了,停止改进 |
这个机制保证了:好的方向上不会过度优化,坏的方向上也不会过度惩罚。
4.3 KL 约束损失:$L^{\text{KL}}$
定义
KL 散度衡量两个概率分布之间的差异:
展开后:
为什么需要 KL 约束
- 防止分布崩溃:如果不限制,Actor 可能会为了追求高奖励,把所有概率都集中到少数几个高奖励的 token,失去多样性
- 保持模型能力:新 Actor 与 SFT 模型相近,保留了原有的知识和一般化能力,不会因过度优化而”忘记”
- 实际部署考虑:过度优化可能导致模型在某些边缘情况下表现很差,或生成有害内容
- 训练稳定性:限制分布变化范围有助于梯度稳定,防止训练发散
权重超参数 $\alpha$
- 典型值:$\alpha = 0.2$
- 含义:平衡追求高奖励和保持分布相似性
- 调优:
- 如果 $\alpha$ 过小:模型过度优化奖励,生成不自然回答
- 如果 $\alpha$ 过大:模型变化不足,无法充分学习到人类偏好
4.4 价值函数损失:$L^{\text{VF}}$
定义
其中:
- $V_\phi(s_t)$:Critic 模型对状态价值的预测
- $V_t^{\text{target}}$:目标价值(由奖励和下一状态价值计算)
目标价值的计算
目标价值通常采用 n-step bootstrap 的方式:
最简单的 1-step 版本:
为什么需要价值函数损失
- 训练 Critic:Critic 需要学会准确评估状态价值,这个损失就是训练信号
- 减少方差:准确的价值估计能更好地作为基线,减少优势函数估计的方差
- 稳定优势计算:优势函数依赖于价值估计,好的 Critic 模型产生更稳定的优势信号
权重超参数 $\beta$
- 典型值:$\beta = 0.5$
- 含义:平衡策略优化和价值函数拟合
- 调优:
- 如果 $\beta$ 过小:Critic 学习不充分,方差大
- 如果 $\beta$ 过大:Critic 过度拟合,策略学习受影响
5. 优势函数的计算
优势函数的准确计算对 PPO 的性能至关重要。在 LLM 的 RLHF 场景中,我们需要特别考虑奖励的稀疏性和长序列的特性。
5.1 Token 级别的即时奖励构造
在 LLM 中,奖励有一个特殊的特点:只有序列末端有实际奖励(来自 RM),中间步骤没有直接的奖励信号。
奖励的构造方式
对于生成序列中的第 $t$ 个 token,我们构造其即时奖励为:
其中:
- $T$:序列长度(生成到 EOS 或最大长度)
- $r_{\text{RM}}$:Reward Model 在序列末端给出的奖励
- $\beta$:KL 惩罚的权重(典型值 0.05-0.2)
关键特点:
稀疏 RM 奖励:
- 中间 token 的奖励为 0($t < T$)
- 只有最后一个 token($t = T$)才获得 RM 的评分 $r_{\text{RM}}$
- 这反映了现实:我们只在完整回答后才评分
密集 KL 惩罚:
- 每个 token 都会产生 KL 惩罚
- 防止策略在追求高奖励时偏离参考模型太远
直观理解:
- 前 $T-1$ 个 token:只受 KL 约束的负值惩罚
- 第 $T$ 个 token:既获得奖励鼓励,也受 KL 约束
5.2 时序差分误差与 GAE
时序差分(TD)误差
基于上面的即时奖励,我们可以计算每个 token 位置的 TD 误差:
三项含义:
- $r_t$:该 token 在该步获得的即时奖励
- $\gamma V(s_{t+1})$:对下一状态价值的折扣期望($\gamma$ 通常设置为 1)
- $V(s_t)$:当前状态价值的预测
$\delta_t$ 的含义:
- 这是一个”惊喜”信号:实际观察($rt + \gamma V(s{t+1})$)vs 预期($V(s_t)$)
- 如果 $\delta_t > 0$:实际比预期更好
- 如果 $\delta_t < 0$:实际比预期更差
- Critic 模型通过最小化 $\delta_t^2$ 来改进价值估计
广义优势估计(GAE)
直接使用 $\delta_t$ 作为优势估计会有方差大的问题。GAE(Generalized Advantage Estimation)通过加权求和多个 TD 误差来平衡偏差和方差:
其中 $\lambda \in [0,1]$ 是平衡参数。
展开式(有限长度):
对于长度为 $T$ 的序列,$t$ 时刻的 GAE 为:
这可以递归计算(效率更高):
GAE 的两个极端:
当 $\lambda = 0$ 时:$A_t^{\text{GAE}} = \delta_t$(单步 TD)
- 低方差,但可能有高偏差(如果 Critic 不准确)
当 $\lambda = 1$ 时:$At^{\text{GAE}} = \sum{l=0}^{\infty} \gamma^l \delta_{t+l}$(蒙特卡洛)
- 低偏差(无模型依赖),但高方差(依赖长期轨迹)
$\lambda$ 的选择:
- 典型值:$\lambda = 0.95$
- 这个值在低偏差和低方差之间取得很好的平衡
5.3 完整的优势计算流程
让我们整理一个完整的算法流程:
算法:Token 级别优势估计
输入:
- 生成序列:$s_0, a_0, s_1, a_1, \ldots, s_T, a_T$
- Reward Model 输出:$r_{\text{RM}}$(在 $t=T$ 时)
- Critic Model:$V_\phi$(对序列中每个位置的评估)
- 超参数:$\gamma$(折扣因子,通常 1),$\lambda$(GAE 参数,通常 0.95),$\beta$(KL 权重)
步骤 1:计算即时奖励
步骤 2:计算 TD 误差
其中当 $t=T$ 时,约定 $V(s_{T+1})=0$。
步骤 3:计算 GAE 优势
末端初始化并递归计算:
并自后向前递归:
步骤 4:使用优势进行更新
得到优势 $A[0], A[1], \ldots, A[T]$ 后:
- 用于 PPO 策略更新:$L^{\text{CLIP}} = \mathbb{E}[\min(r_t A_t, \text{clip}(r_t) A_t)]$
- 用于 Critic 更新:$L^{\text{VF}} = \mathbb{E}[(V(st) - (r_t + \gamma V(s{t+1})))^2]$
5.4 一个具体例子
让我们用一个简单的数值例子来演示整个计算过程。
假设:
- 序列长度 $T = 3$(3 个 token)
- $\gamma = 1$,$\lambda = 0.95$
- $r_{\text{RM}} = 5$(这是一个好回答)
- $\beta = 0.1$
- Critic 的价值估计:$V(s_0)=2, V(s_1)=3, V(s_2)=4, V(s_3)=0$(边界)
计算过程:
即时奖励(假设 KL 项都是 -0.1)
- $r[0] = -0.1$
- $r[1] = -0.1$
- $r[2] = 5 - 0.1 = 4.9$
TD 误差
- $\delta[0] = -0.1 + 1 \times 3 - 2 = 0.9$
- $\delta[1] = -0.1 + 1 \times 4 - 3 = 0.9$
- $\delta[2] = 4.9 + 1 \times 0 - 4 = 0.9$
GAE 优势(从后向前)
- $A[2] = 0.9$
- $A[1] = 0.9 + 0.95 \times 0.9 = 1.755$
- $A[0] = 0.9 + 0.95 \times 1.755 = 2.567$
结果解释:
- 所有 token 都有正的优势,鼓励增加其生成概率
- 越早的 token 由于能”看到”后续的奖励,优势越大
- 最后一个 token 的优势最小(0.9),因为它直接看到 RM 的奖励
总结
PPO 是一个巧妙且实用的强化学习算法,在 LLM 的 RLHF 训练中发挥了关键作用。它的核心优势包括:
- 稳定的策略更新:通过裁剪机制限制策略偏离,避免训练不稳定
- 灵活的约束机制:通过 KL 散度约束保持模型的原有能力
- 高效的方差减少:通过优势函数作为基线大大降低学习信号的方差
- 实用的设计:多个可调的超参数让算法在不同场景下都能表现良好
理解 PPO 的这些核心原理对于:
- 深入掌握 LLM 的后训练方法
- 调优 RLHF 训练过程
- 开发新的强化学习训练方法
都是至关重要的。希望通过本文的详细讲解,能帮助你充分理解 PPO 在 LLM 训练中的应用与实现细节。